关系抽取的数据集并不多,在各种paper中常见的数据集为ACE04和ACE05数据集和 SemEval-2010任务8开发集,而中文领域相关数据集暂时还未发现。另外还有NYT10数据集。
一.远程监督学习步骤
- 从知识库中抽取存在关系的实体对
注意:可以从现有知识库得到,但是这样的知识库很难找到,即使wikidata也是通用型的知识库。所以,可以采用先对文书进行分词的方法,提取名词作为实体,人工阅读实体定制实体可能存在的关系。
从非结构化文本中抽取含有实体对的句子作为训练集(包含实体对的句子就是训练集)
Github项目源码:https://github.com/thunlp/NRE
二. 基于Bootstrap的方法
利用少量的实例作为初始种子集合,然后利用pattern学习方法进行学习,通过不断的迭代,从非结构化数据中抽取实例,然后从新学到的实例中学习新的patter并扩充pattern集合。

三. 远程监督学习
从如wikipedia(infobox)、本体或者人工标注小规模实体对,将这些高质量关系实体对作为种子,从web中挖掘包含已知实体对的大规模文本,作为自动标注的语料库,然后使用Supervised的方法解决关系抽取问题。
假如高质量关系实体对来自知识库KB(也可来自人工标注),那么将KB当中的关系引入到正常的自然语言句子当中进行训练,例如‘苹果’和’乔布斯’在KB中的关系是CEO,那么我们就假设类似于“【乔布斯】发布了【苹果】的新一代手机”的句子上存在CEO的关系,如此,利用KB对海量的文本数据进行自动标注,得到标注好的数据(正项),再加入一些负项,随后训练一个分类器,每个分类是一个关系,由此实现关系抽取。
结合了bootstrapping和监督学习的长处,使用一个大的数据库来得到海量的seed
example,然后从这些example中创建许多的feature,最后与有监督分类器相结合。

学习阶段:
使用命名标注器标注实体,比如我们要识别某个人是否属于某个组织,需要标注persons
organizations和locations对在freebase中出现的实体对提取特征,构造训练数据
模型训练
测试阶段:
使用命名实体标注器标注实体,persons organizations 和 locations
在句子中出现的,每对实体都被考虑作为一个潜在的关系实例,作为测试数据
使用训练后的模型对实体进行分类
其他博客:http://www.sohu.com/a/131648756_465975
四. 知识库的搭建(或者叫做信息抽取):
https://www.msra.cn/zh-cn/news/features/b9b67ac0-6a59-4a85-ba5f-d288cebbc1ec
分为以下几种方式:(1)人工编辑知识库(2)利用大众智慧,让互联网用户定期向知识库提供知识(3)设计自动或者半自动算法,从现有的自然语言文本提取,也叫做信息抽取。信息抽取算法往往依赖于所要进行的知识提取任务,下面先介绍知识类型和提取任务
4.1 知识类型
知识图谱中一般有三类节点:实体,语义类(一类实体的集合),文本(作为实体和语义类的描述)
知识图谱中节点间的边:实体-语义类(从一个实体指向他所属的语义类),子类-父类(从一个语义类指向其父类),属性(从一个实体指向它的属性值,所有实体和语义类都拥有一个特殊的属性“名字”,它指向文本类型的结点,表示此实体或语义类的名字或自然语言表达(如中文名、英文名等))
关系:即一个函数,把k个图节点(实体、语义类和文本节点)映射到布尔值的函数
4.2 知识提取任务
知识提取的任务是构建知识图谱中节点和所有边,具体子任务包括:
实体名提取(提取实体名并构造实体名列表),
语义类提取,(构造语义类并建立实体和语义类的关联)
属性和属性值抽取,(为语义类构造属性列表,并提取类中所包含实体的属性值)
关系抽取(构造节点间的关系函数,并提取满足关系的节点元祖)
实体名提取:
主要任务是构建一个词表,词表中主要包含实体名如“中国”,和语义类名称如“国家“。常见的词表构建方法:从百科类站点提取,利用模式从自然文本提取以及NER技术。最简单的方法是从百科类站点(如维基百科、百度百科、互动百科等)的标题和链接中提取实体名。基于模式的方法从网页和句子中抽取词的并列相似度和上下位关系信息,其副产品是一个词表。这种方法能够覆盖比较广的领域和实体类型,与从百科类站点提取实体名的方法相比,对中低频词具有更高的覆盖率,但所得到的词表精度要低。
语义类抽取:
从文本中自动抽取信息来构造语义类并建立实体和语义类的关联
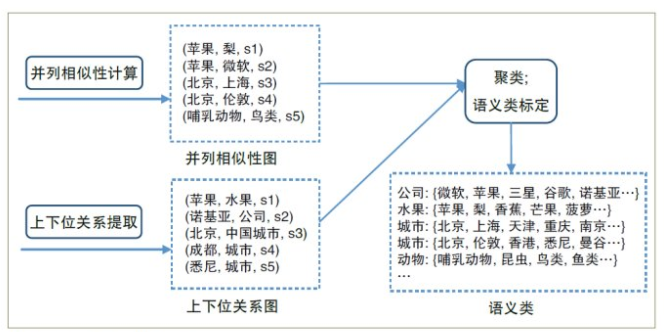
并列相似度计算:用计算相似度算法便可以完成。上下位关系提取:最简单的办法是解析百科站点的分类信息。其次可以采用模式匹配(hearest,Isa等)。模式进行模式匹配被认为是比较有效的上下位关系抽取方法。下面是这些模式的中文版本(其中NPC
表示上位词,NP 表示下位词):
NPC { 包括| 包含| 有} {NP、}* [ 等|等等]
NPC { 如| 比如| 像| 象}{NP、}*
{NP、}* [{ 以及| 和| 与} NP] 等NPC
{NP、}* { 以及| 和| 与} { 其它| 其他}NPC
NP 是 { 一个| 一种| 一类}NPC
语义类生成:包括聚类和语义类标定两个子模块。聚类的结果决定了要生成哪些语义类以及每个语义类包含哪些实体,而语义类标定的任务是给一个语义类附加一个或者多个上位词作为其成员的公共上位词
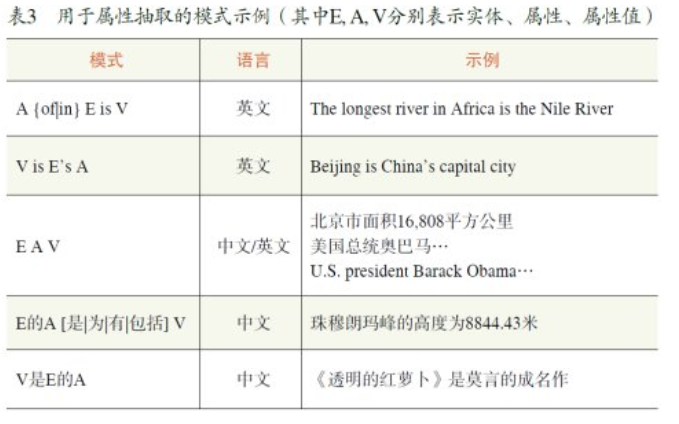
属性和属性值抽取:
属性提取的任务是为每个语义类构造属性列表(如城市的属性包括面积、人口、所在国家等),而属性值提取则为一个语义类中所包含的实体(如北京)附加属性值(如其面积、人口、所在国家等)。常见的属性和属性值抽取方法包括从百科类站点中提取,从垂直网站中进行包装器归纳,从网页表格中提取,以及利用手工定义或自动生成的模式从句子和查询日志中提取。
此过程分两个步骤,第一个步骤通过将输入的模式作用到句子上而生成一些(词,属性)元组,这些数据元组在第二个步骤中根据语义类进行合并而生成(语义类,属性)关系图。在输入中包含种子列表或者语义类相关模式的情况下,整个方法是一个半监督的自举过程,分三个步骤:
模式生成:在句子中匹配种子列表中的词和属性从而生成模式。模式通常由词和属性的环境信息而生成。(根据种子模板生成更多的数据)
模式匹配
模式评价与选择:通过生成的(语义类,属性)关系图对自动生成的模式的质量进行自动评价并选择高分值的模式作为下一轮匹配的输入。
关系提取
关系的基本信息包括参数类型、满足此关系的元组、自然语言表达方式(称为模式)等。例如关系BeCurrencyOf(表示一种货币是一个国家的货币)的基本信息如下:
Business.Currency和Loc.Country 分别表示货币和国家两个语义类
参数类型:(Business.Currency, Loc.Country)(第一个参数是货币,第二个是国家)
模式如下:

元组:(人民币,中国);(欧元,德国);(第纳尔,伊拉克)
半监督关系抽取的主要思路是自举法,即对每类关系提供少量模式或实体元组作为种子,然后利用类似上图的过程得到更多的模式和元组。不同的半监督关系抽取方法遵循类似的流程,但采用不同的模式生成、模式匹配以及模式评价和选择策略,因此会得到不同的抽取效果。在有监督和半监督方法中,一般假定关系的参数类型和一部分元组是已知的。这些方法的输入还可能包含一些模式(作为种子)或者标定好的句子(作为训练数据)。
五. 可采用的网络训练方式
深度学习,避免人工特征工程。利用双层的 LSTM-RNN 模型训练分类模型,第一层
LSTM 输入的是词向量、位置特征和词性来识别实体的类型。训练得到的 LSTM
中隐藏层的分布式表达和实体的分类标签信息作为第二层 RNN
模型的输入,第二层的输入实体之间的依存路径,第二层训练对关系的分类,通过神经网络同时优化
LSTM 和 RNN 的模型参数。
六. OpenIE工具的使用
https://www.jianshu.com/p/81d131e8adea
网上看到openIE工具对关系抽取有用,先记下来,以后研究,哈哈,等下一篇博客吧。
它假定实体被发现,然后消除歧义,并且实体之间的文本利用OpenIE工具在开放域关系进行转换。 实体和关系的嵌入创建在在同样的低维空间中。OpenIE文本到最相似固定Schema关系的映射是通过他们之间的嵌入的相似度计算的。这个系统是通过排序误差来训练的。给定一个OpenIE关系,这个想法给含有弱标签的配对要比KG中的随机关系(通过Negative
Sampling)要更高的得分。这个文件更进一步,一旦文本中提出去三元组,这个模型就学出实体和它们之间关系的空间嵌入值。在这个嵌入空间中,我们期望关系r对应到E1到E2的转化。这个空间嵌入不仅由找到的三元组创建,也包括原始KG里面的所有三元组。
在上面提供的所有示例中,找到的关系在最初提出的固定Schema之内。 然而,如前所述,不存一个固定Schema能够完美的适合所有可能的文本能够表达的两个实体间的关系。
七. 模型构建
- 方案一:远程监督学习
该方式选择从已有知识库的话,需要知道法律背景下的实体对以及其对应关系有哪些,难点是很难找。所以这里得到实体对以及关系采用自动化的方式,通过分词得到的名词一般是实体,再由人工来定制实体关系,生成少量的种子数据。
- 基于相似度生成更多训练数据的方法