- LSTM可以处理长距离依赖的问题
在之前的RNN沿着时间线反向传播中,很容易出现梯度消失与梯度爆炸的问题,无法向前看很多个词语。那么梯度消失会导致什么后果呢?
这里我们针对交叉熵损失函数对权重矩阵W梯度的计算公式讨论:权重数组W最终的梯度是各个时刻的梯度和(前面RNN已经证明)

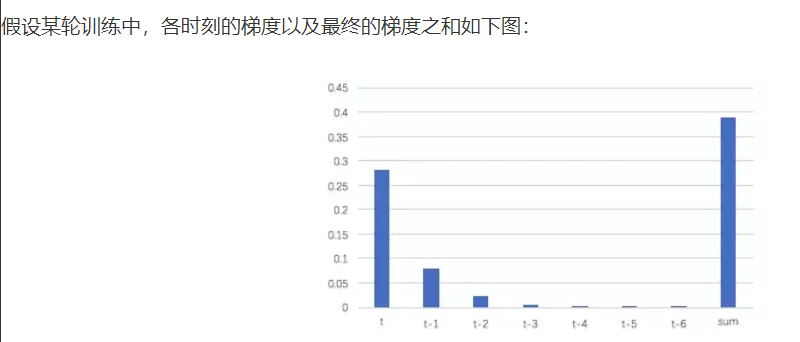
这里解释一下为什么时间越往前,损失函数对权重数组W的梯度会明显变小
损失函数对权重数组W的梯度=该时刻的误差项*上一时刻循环层的输出st-1,具体细节参见RNN部分。从上图的t-3时刻开始,梯度已经几乎减少到0了。那么,从这个时刻开始再往之前走,得到的梯度(几乎为零)就不会对最终的梯度值有任何贡献,这就相当于无论t-3时刻之前的网络状态h是什么,在训练中都不会对权重数组W的更新产生影响,也就是网络事实上已经忽略了t-3时刻之前的状态。这就是原始RNN无法处理长距离依赖的原因。
既然我们无法通过反向传播实现长距离依赖,假如我们能够记录之前很久的状态,用记录的结果直接影响当前的时刻即可。
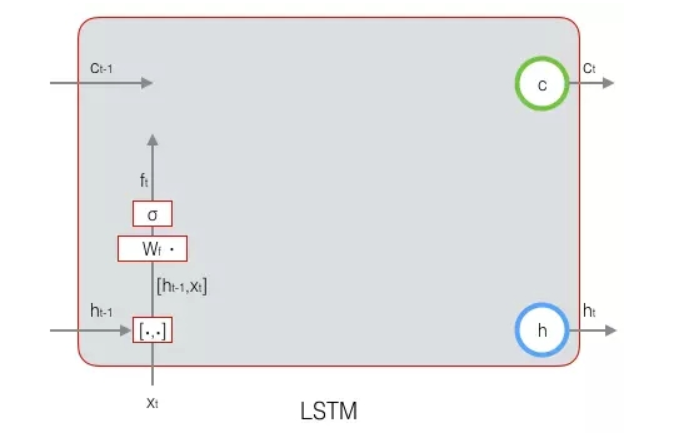
其实,长短时记忆网络的思路比较简单。原始RNN的隐藏层只有一个状态,即h,它对于短期的输入非常敏感。那么,假如我们再增加一个状态,即c,让它来保存长期的状态,那么问题不就解决了么?新增加的状态c,称为单元状态(cell
state)。我们把上图按照时间维度展开:

LSTM的输入有三个量:
当前时刻网络的输入xt
上一时刻LSTM的输出值ht-1
上一时刻的单元状态ct-1
LSTM的输出有两个:
当前时刻LSTM输出值ht
当前时刻的单元状态ct
注意:x,h,c都是向量
长期状态c(单元状态)的控制:LSTM的思路是使用三个控制开关。第一个开关,负责控制继续保存长期状态c;第二个开关,负责控制把即时状态输入到长期状态c;第三个开关,负责控制是否把长期状态c作为当前的LSTM的输出。

- 长短时记忆网络的前向计算
计算输出h和单元状态c,LSTM采用了门的概念来实现上述开关的作用。门实际上就是一层全连接层,它的输入是一个向量,输出是一个0到1之间的实数向量。假设W是门的权重向量,是偏置项,那么门可以表示为:

换言之,假如当门(用一层神经网络实现)的输出为零向量,用该零向量乘以需要被控制向量得到零向量,相当于需要被控制向量所有成分都不通过该门。假如当门(用一层神经网络实现)的输出为1向量,用该1向量乘以需要被控制向量得到原向量,相当于需要被控制向量所有成分都通过该门。然而,实际上,实现了门的神经网络的输出并不是完全的零向量或者1向量,而是介于(0,1),所以,所有门的状态都是半开半闭,即相当于以一定比例的成分通过该门。
- 各个门的分析
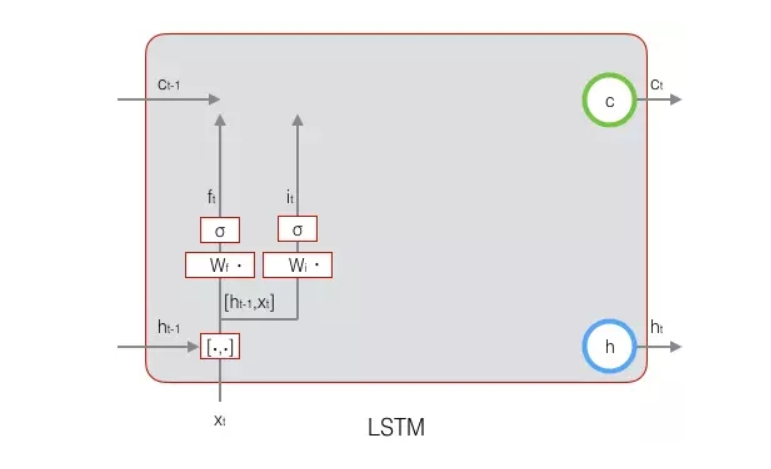
LSTM用两个门来控制单元状态c的内容:
遗忘门:决定了上一时刻的单元状态ct-1有多少成分保留到当前时刻ct
输入门:它决定了当前时刻网络的输入xt有多少成分保存到单元状态ct
LSTM用输出门来控制单元状态ct有多少输出到LSTM的当前输出值ht
- 遗忘门

注意:通常单元状态c的维度dc显示与隐藏层的维度dh是相同的,权重矩阵Wf是由Wfh与Wfx两部分组成的。最后我们得到的遗忘门输出向量维度为dc*1的列向量,用于控制长期状态ct-1有多少保留到下一个状态。
- 输入门
- 接下来,计算用于描述当前输入的单元状态

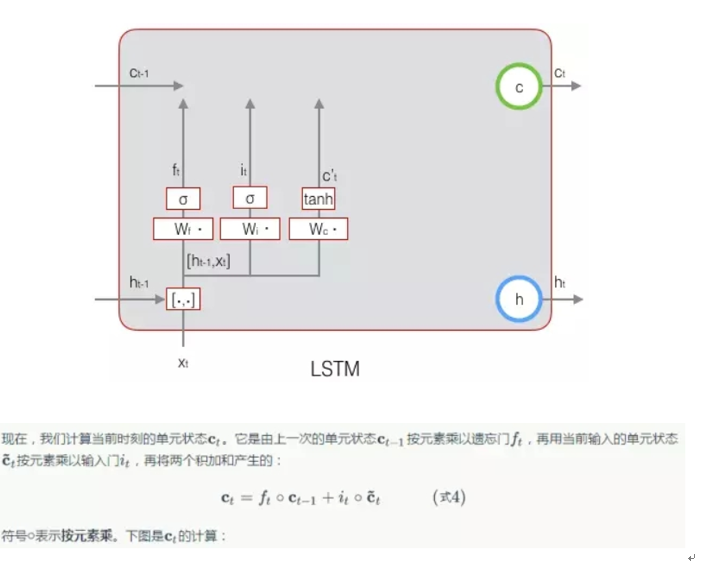
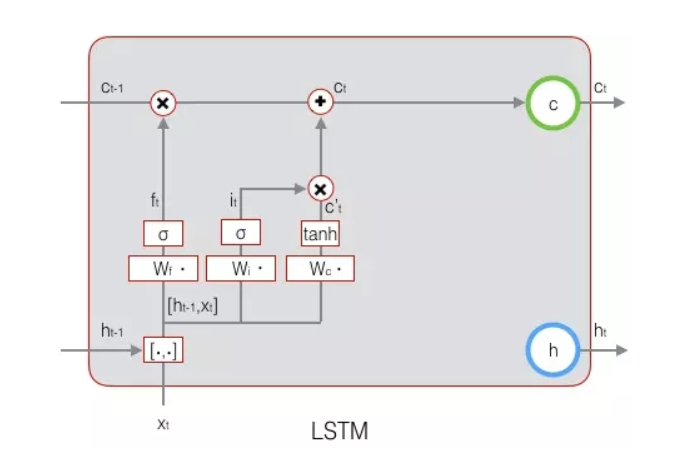
总结:如何计算得到当前时刻的单元状态ct是重点,来源于上一时刻的长期状态ct-1与当前输入的单元状态c’t(由Wc*[ht-1,xt]+bc再作用于tanh激活函数可以得到),这两个都有少部分进入当前时刻的单元状态ct,具体多少由遗忘门ft与输入门it控制。(门的激活函数是sigmoid函数,计算当前输入的单元状态c’t所用的激活函数是tanh函数)。
- 输出门

输出门激活函数还是为sigmiod函数,每个维度值域为(0,1) ,只允许少量成分通过。

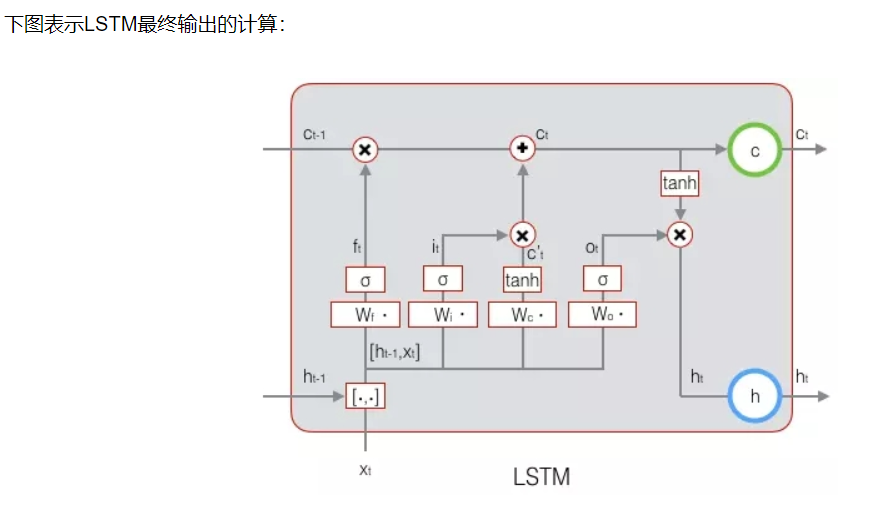
- LSTM的训练

我们设定门的激活函数为sigmoid函数,输出的激活函数为tanh函数。
LSTM的参数有八组:遗忘门、输入门、输出们的权重与偏置,以及计算单元状态的权重矩阵Wc与bc。
Wfh对应着输入项ht-1部分,维度为dc*dh,Wfx对应着输入项xt部分,维度为dc*dx

这里请注意,非常重要!!!!!!!!!!!!
LSTM的误差项定义,不同于RNN,LSTM不再是损失函数对加权求和的偏导,而是定义为对输出ht的偏导。


4.1 沿着时间线反向传递

因为Ot,ft,it等它们都有共同因子[ht-1,xt]




一定要非常清楚δt与δf,t,δi,t,δo,t的定义式才能看懂推导
4.2 沿层数的反向传递

- 权重更新
有前面RNN的推导,我们知道Wfh,Wih,Wch,Woh的权重梯度为各个时刻的梯度之和,所以需要先求出它们在t时刻的梯度,才能求出最终的梯度。



- LSTM的变体GRU
GRU对LSTM做了两个大改动:
将输入门、遗忘门、输出门变为两个门:更新门Zt和重置门rt。
将单元状态与输出合并为一个状态:h

总结:相比于LSTM有三个输入与2个输出,GRU只有两个输入和一个输出