美团机器学习实战
问题建模
评估指标
精确率与准确率是有去别的,精确率是一个二分类评估指标,准确率评估可用于多分类
精确率:二分类混淆矩阵算出的精确率
准确率
$准确率=\frac{TP+TN}{TP+FP+FN+TN}=\frac{1}{n} \sum\limits_{i=1}^nI(f(x_i)=y_i)$
ROC与AUC
在众多机器学习模型中,很多模型输出是预测概率,使用精确率与召回率进行评估时,还需要对预测概率设置分类阈值。这使得模型多了一个超参数,并且该参数会影响模型的泛化能力。ROC曲线可解决上述问题。纵坐标为真正率,横坐标为假正率。AUC即ROC曲线下的面积,取值越大说明模型越可能将正样本排在负样本前面,这样由某阈值切分后,两边的数据将会变得更加的“纯”。
AUC的统计特性:随机挑选一个正样本和负样本,分类器将正样本排在前面的概率。
AUC的意义:考虑的是样本的排序质量,与排序误差有密切的联系
对数损失
对数损失最小化本质上是利用样本中的已知分布,求解导致这种分布的最佳参数,使这种分布出现概率最大。它衡量的是预测概率分布与真实概率分布的差异性,取值越小越好。与AUC不同,对数损失对预测概率极其敏感;而AUC对排序敏感,对预测分数不是太敏感。
排序评估指标
MAP:平均准确率均值。先计算一次查询的平均准确率,再计算Q次查询的总体准确率
《美团机器学习实战》P9
NDCG排序评估指标:相对于MAP的相关性只能用0/1二值描述,NDCG的相关性可以分更多的等级。NDCG的分数表明的是一次查询的排序返回结果的质量。《美团机器学习实战》P10
样本选择
一般需要切分出验证集合,用来验证和测试模型
特征工程
数值特征
对于目标变量为输入特征的光滑函数的模型,如线性回归、逻辑回归,其对输入特征大小敏感,需要对特征进行归一化。而对于那些基于树的模型,如随机森林,梯度提升树,其对输入特征的大小不敏感,无需将特征进行归一化。
- 分桶:方法一:均匀分桶;方法二:分位数分桶(对于固定宽度分桶,如果数值变量的取值存在很大间隔,那么有些桶中将会没有数据)
- 数值缩放,归一化到(0,1)
- 缺失值处理:利用平均值填写。有一些模型可以自动处理缺失值,如XGBOOST、LightGBM等。
- 特征交叉:利用FM与FFM。特征交叉可以在线性模型中引入非线性性质,提升模型的表达能力。
类别特征
独热编码喂给模型
散列编码:对于有些取值特别多的类别特征,可以在独热编码之前先对类别进行散列编码,这样可以避免特征矩阵过于稀疏。
有监督编码方法(基于目标变量对特征进行编码)
例如,对于分类问题,采用交叉验证的方式,将样本划分为5份,针对其中每一份数据,计算类别特征取值在另外四份数据中每个类别的比例。举例:对广告主ID进行编码,利用广告主ID过去固定一段时间的点击率,对广告主的ID进行目标编码。
时间特征
时间序列不仅包含一维的时间变量,还有一维其他变量,如股票价格、天气温度等。对于时间的编码,可以利用前k个时刻的相关值作为特征使用。比如对于回归问题,将前k个取值的均值用于编码时间;对于分类问题,将前k个时刻中每个类别的分布作为特征。
文本特征
文本推荐,文本检索:Jaccard相似度,编辑举例,词向量分布式表示
特征选择
过滤方法(不需要使用任何机器学习方法)
单变量过滤方法
基于特征变量与目标变量之间的相关性或互信息。按照特征变量与目标变量之间的相关性进行特征排序,过滤掉最不相关的特征变量。缺点:可能选出的特征存在冗余。
多变量过滤方法
基于相关性与一致性的特征选择
皮尔逊相关系数,衡量X与Y的相关性
$r=\frac{ \sum \limits _{i=1}^n {(X_i- \overline{X}) (Y_i- \overline{Y})} }{ \sqrt{ \sum \limits_{i=1}^n (X_i- \overline{X})^2 } \sqrt{ \sum \limits_{i=1}^n (Y_i- \overline{Y})^2 }}$
假设检验
互信息
相关特征选择
封装方法
是特征子集搜索和评估指标相集合的方法,前者提供候选的特征子集,后者则基于新特征子集训练一个模型并进行评估。封装方法需要对每一组特征子集训练一个模型,所以计算量很大。
- 启发式搜索:序列向前选择,特征子集从空集开始,每次只加入一个特征,这是一种贪心算法。序列向后选择,特征子集从全集开始,每次删除一个特征。
嵌入方法
嵌入方法将特征选择嵌入到模型的构建过程中,具有封装方法和机器学习方法相结合的有点。嵌入方法最经典的例子是LASSO回归,L1正则。还有决策树方法,也可以进行特征选择。
计算广告学
- RTB:实时竞价。综合利用算法、大数据技术在网站或移动应用上对在线的流量实时评估价值,然后出价的竞价技术
- Ad Exchange:广告交易平台。同时投放了大量的DSP和SSP,给双方提供一个交易场所。将SSP(供应方平台)的广告展示需求以拍卖的形式卖给DSP方。有点像股票中的证券大厅角色。
- DSP(需求方平台):为各广告主或者代理商提供实时竞价投放平台,可以在该平台上管理广告活动及其投放策略,并且通过技术和算法优化投放效果,从中获得收益
- SSP(供应方平台):为各媒体提供一致、集成的广告位库存管理环境
- CTR(点击率):广告点击与广告展现的比例,这是广告主、各大DSP厂商都非常重视的一个数字,从技术角度看,这一数字可以影响到广告的排序、出价等环节,从业务来看,这是运营人员的考核指标之一
- CVR(转化率):转化(主要由广告主定义,可以是一次下单或是一次下载app等)次数与到达次数的比例
- https://www.zhihu.com/question/23458646/answer/25535257
- https://www.zhihu.com/search?type=content&q=SSP%E4%B8%8EDSP
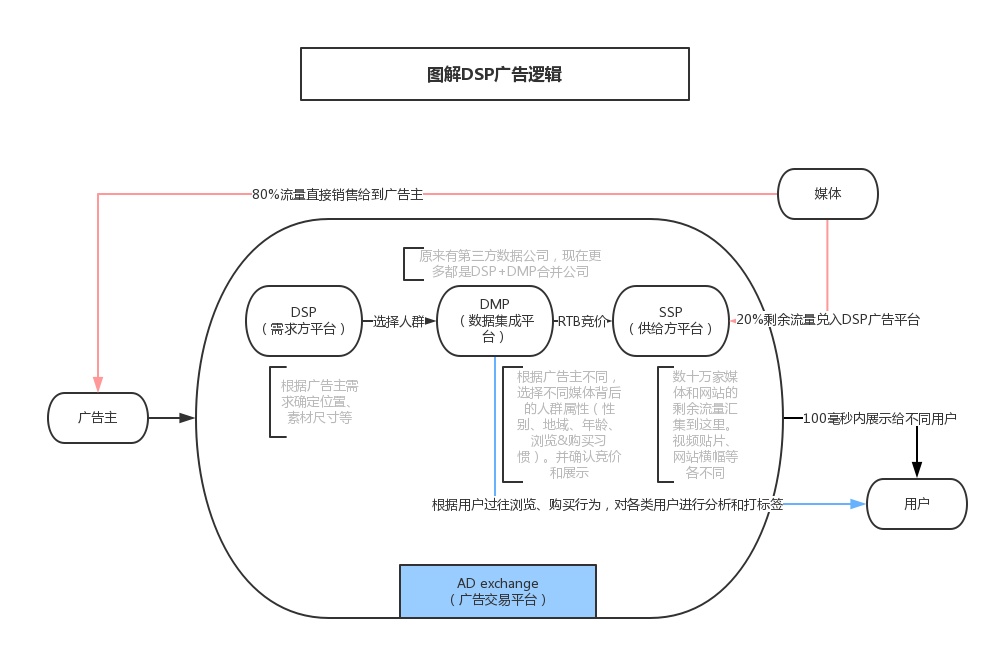

- 实时竞价广告交易平台(Ad Exchange):广告交易所;需求方平台(DSP):广告提供方,代表广告主,需求做广告的人;供给方平台(SSP):流量提供方,代表媒体,生产、售卖流量的人;数据管理平台(DMP):给访问广告的人打标记标签的人。比如一个汽车类的广告主,需要投放广告,那他去找一家dspdsp去ad exchnge中,购买ssp方提供的流量,展示汽车的广告,购买交易过程中,先咨询下dmp,这个访客是否是关注汽车的人,是才购买,不是则可以不购买。