学习曲线
误差loss曲线图
均方误差曲线图:loss与训练数据量(时间)的关系
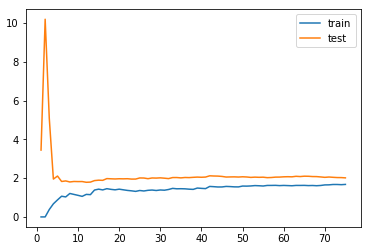
随着训练数据的增多,样本点增多,模型越难拟合住所有数据,相应的均方误差会逐渐累积增大。但随着训练数据的增大,均方误差的积累量越来越少,模型相应会变得稳定。
测试数据集合最开始的loss很大,当训练数据量增大到一定程度,test的loss就会稳定,并且test的loss一定会比train高。
欠拟合:两曲线趋于稳定的点都比较高,也就是train loss和valid loss都比较高,但两者差距不是很大
过拟合:两曲线区域稳定后间隔差距很大,test的loss远高于train loss,这是因为模型过拟合,无法很好的在测试集合上泛化。
在机器学习中,模型过于简单会导致欠拟合,过于复杂会导致过拟合。那么适中才合适
验证曲线刻画的是模型loss和模型参数之间的关系。
下面这幅图是loss和模型复杂度之间的关系:(这个图也叫做bias与variance权衡)
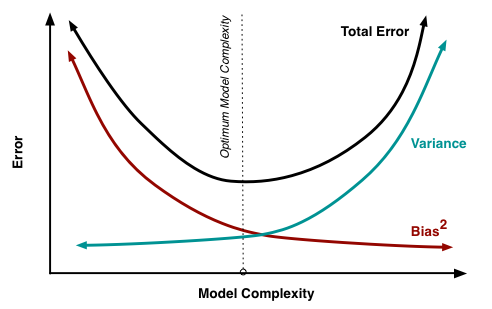
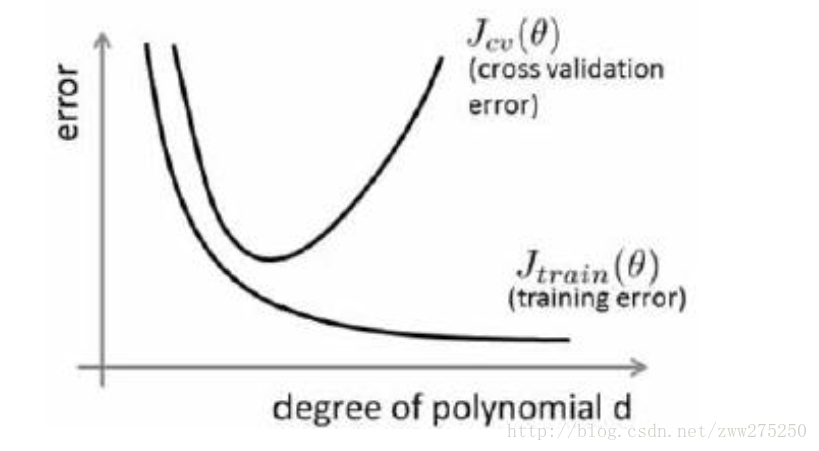
模型复杂度与train loss和valid loss之间的关系