Tensorboard可视化
Tensorboard在展现计算图的时候,默认情况下,只有顶层节点才会展示。但我们可以点击顶层节点进入内部,观察顶层节点的内部细节。
1 | import tensorflow as tf |
结果是得到了下面三个操作名:
- hidden/alpha
- hidden/weights
- hidden/biases
默认地,三个操作名会折叠为一个节点并标注为hidden。其额外细节并没有丢失,你可以双击,或点击右上方橙色的+来展开节点,然后就会看到三个子节点alpha,weights和biases了。
如果要在一张图中显示多个模型的结果,可以如下做。log_filepath设置为/temp/tensorflow,该文件夹下创建两个文件。一个run_a文件夹,一个run_b文件夹,分别存放模型a和b的运行结果。
最后在tensorboard指令的时候–logdir的参数定位在/temp/tensorflow
法二:tensorboard上显示不同训练模型曲线的方法
tensorboard –logdir=run1:“路径1”,run2:“路径2” –port=6006
由于存在训练集合和测试集合,所以在定义tf.summary.FileWriter的时候应该定义两个
train_writer = tf.summary.FileWriter(FLAGS.log_dir + ‘/train’, sess.graph)
test_writer = tf.summary.FileWriter(FLAGS.log_dir + ‘/test’)
什么时候应该加tf.summary进行统计
计算图的记录
在准备开始训练的时候,记录计算图的流程,如:
1
2
3
4
5with tf.Session() as session:
session.run(init)
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('./logs/summary', session.graph)要添加scalar与histgram可以在定义图的时候就定义好
1
2tf.summary.histogram()
tf.summary.scalar()真正加到log日志文件中是在session会话中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26# 初始化Variable
init = tf.global_variables_initializer()
# 打开session
with tf.Session() as session:
# 运行初始化
session.run(init)
# 调用merge_all(),将前面添加的所有histogram和scalar合并到一起,方便观察
merged = tf.summary.merge_all()
# 同样写入到logs中
writer = tf.summary.FileWriter('./logs/summary', session.graph)
training_feed_dict = {inputs: X, targets: y_.eval()}
for i in range(epochs):
# 训练的时候,第一个传入merged对象,返回summary
summary, _, l = session.run(
[merged, optimizer, loss],
feed_dict=training_feed_dict)
if not i % 50:
print('Epoch {}/{} '.format(i + 1, epochs),
'Training loss: {:.4f}'.format(l))
# 每50步,将summary对象添加到writer写入磁盘,最后来观察变化
writer.add_summary(summary, i)自定义summary
1
custom_sm = tf.Summary(value=[tf.Summary.Value(tag="accuracy", simple_value=acc)]) writer.add_summary(custom_sm, step)
什么时候会用到这个?
一般是在session会话中算出一个标量,需要直接将这个标量加到Tensorboard中,而不是像传统那样在计算图中添加。
对于Histgram直方图的理解
https://blog.csdn.net/jk981811667/article/details/78864215
https://blog.csdn.net/windows2/article/details/78229604
https://blog.csdn.net/weixin_35653315/article/details/72471312
histogram展示的统计变量随着step的分布的变化情况,当研究梯度消失,不同层间的权重分布,观察有些异样现象,都是通过这个。TensorFlow图中某些张量的分布随时间如何变化
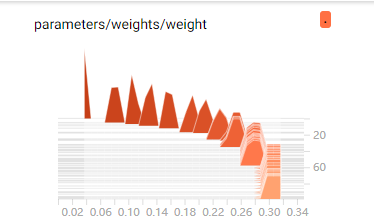
这个结果在我github中的TestTensorboard代码中的test可以看到,模拟的线性回归,weight是一个标量。可以看到在step为0的时候,对应有一个很尖的数据,这是的频率显示为1,这也反应了开始训练时,weight初始化为一个数,并且该数的频率为1。随着时间的进行,当训练到100步左右的时候,可以看到在此时,前100步中,weight值为0.3出现的频率为0.3左右(相当于出现了30次左右),weight为0.307或者0.297出现的频率同样是0.3左右。所以可以得出,当训练完成后,weight值约为0.3左右。(因为前100步中大约有40次为0.3,大约30次为0.307,大约30次为0.297).
分布图Distribution的理解
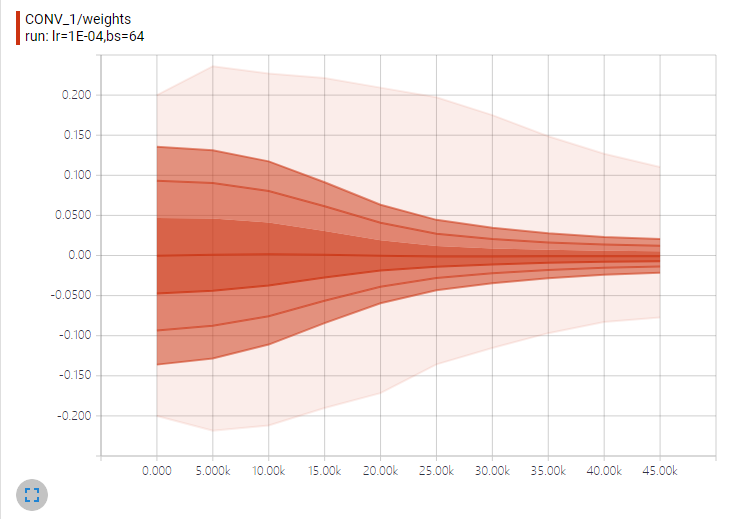
横轴表示训练步数,纵轴表示权重值。而从上到下的折现分别表示权重分布的不同分位数:`[maximum, 93%, 84%, 69%, 50%, 31%, 16%, 7%, minimum]