Tensorflow编程bug
执行sess.run(某tensor)或者某tensor.eval()函数的时候,已知卡住,也不报错。注意输入数据采用多线程的方法
相关代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21with tf.Session() as sess:
model =create_model(sess,FLAGS)
coord=tf.train.Coordinator()
threads=tf.train.start_queue_runners(coord=coord)
with tf.device('/cpu:0'):
fact_batch_words,batch_laws=inputs(FLAGS.data_dir,FLAGS.batch_size,vocab_dict)
try:
step=0
while not coord.should_stop():
start_time=time.time()
_, loss, accuracy = model.step(sess, fact_batch_words, batch_laws, dropout=FLAGS.dropout,forward_only=False,sampling=False)
time_use=time.time()-start_time
if step%100==0:
print('Step %d:loss=%.2f(%.3sec)'%(step,loss,time_use))
step+=1
except tf.errors.OutOfRangeError:
print('Done training for %d epoches,%d steps'%(FLAGS.num_epoches,step))
finally:
coord.request_stop()
coord.join(threads)
sess.close()问题发现:创建队列的线程在with tf.device中声明,而我们启动线程队列的命令在前面,那你后面当然拿不到数据了。所以我们应该将inputs()函数定义在启动线程队列之前。
对于同时新建图和会话,并在一个函数下定义一个图的结构以及会话session的执行,可以用:
1
2with tf.Graph().as_default(),tf.Session() as sess:
接下来就可以写相关的代码了。除此之外,我们解释一下这个函数在哪定义计算图的。请看下文:
1
model =create_model(sess,FLAGS)
这个函数会创建一个Model对象,而创建Model对象时会执行构造函数init(),而我们的计算流图就是在这个构造函数中定义的。在创建了Model过后,会根据是否有ckpt文件,而选择从model文件中恢复,或者新建一个Model。但是,如果是新建一个Model,需要执行sess.run(tf.initialize_all_variables())函数进行初始化。
Coordinator线程协调器的作用
https://blog.csdn.net/DaVinciL/article/details/77342027
用来管理session中的多个线程,可以用来同时停止多个工作线程并且向那个在等待所有工作线程终止的程序报告异常,该程序在捕获到异常后就会终止所有线程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14try:
while not coord.should_stop():
print '************'
# 获取每一个batch中batch_size个样本和标签
image_batch_v, label_batch_v = sess.run([image_batch, label_batch])
print(image_batch_v.shape, label_batch_v)
except tf.errors.OutOfRangeError: #如果读取到文件队列末尾会抛出此异常
print("done! now lets kill all the threads……")
finally:
# 协调器coord发出所有线程终止信号
coord.request_stop()
print('all threads are asked to stop!')
coord.join(threads) #把开启的线程加入主线程,等待threads结束
print('all threads are stopped!')当线程一直在运行,直到抛出抛出OutOfRangeError的时候,会请求线程停止coord.request_stop(),然后等着停止即可。那么有同学会问,为什么要设置while not coord.should_stop(),那是因为我们需要循环取batch的数据,如果不加这个循环条件,无法做到循环的获取batch的数据。
tf.Coordinator主要用于协同多个线程一起停止,并提供了should_stop、request_stop、join三个函数。在起订线程之前,需要先声明一个tf.Coordinator类,并将这个类传入每一个创建的线程中。启动的线程需要一直查询tf.Coordinator类中提供的should_stop函数,当这个函数的返回值为True时,则当前线程也需要退出。每一个启动的线程都可以通过调用request_stop函数来通知其他线程退出。当某一个线程调用request_stop函数之后should_stop函数的返回值将会被设置为True,这样其他的线程就可以同时停止了。
TypeError:feed cannot be a tf.Tensor object.Acceptable feed values include python scalars,strings,lists,or numpy ndarrays.
建立数据队列,从队列中获取batch_laws和batch_fact,然后sess.run计算图中的某个操作,batch_laws和batch_fact通过feed_dict的方式传入图中,报了上述错误。原因分析:batch_laws仅仅是tensorflow计算图中定义好的,实际上他并不是一个实际的数据,仅仅是一个Tensor,feed必须是实际的数据。实际的数据需要通过sess.run()来获得。所以在用sess.run(执行train_op)的时候,需要sess.run(batch_laws)
有关tensorflow各种初始化函数
对于dunamic_rnn的理解。参考代码中相关的测试代码。在LSTMClassifier中
1
2
3layers = [tf.nn.rnn_cell.BasicLSTMCell(num_units=rnn_hidden_size,state_is_tuple=True) for _ in range(2)]
stacked_cell=tf.nn.rnn_cell.MultiRNNCell(layers)假设层数为2,那么dynamic_rnn返回值为outputs与state。outputs很好理解,维度为[batch_size,time_step,hidden_size]。那么如何理解state?state是最后一个时间步的输出,所以state的形状为[layernum,2,batch_size,hidden_size],且数据类型为LSTMTuple的数据,是元组state[-1][1]就是先取最后一层,然后再取h,那么综合下来就是取最后一层的h_state。
多标签分类的one_hot化
1
2
3>>> from sklearn.preprocessing import MultiLabelBinarizer
>>> mlb = MultiLabelBinarizer(classes=[e for e in np.arange(10)])
>>> mlb.fit_transform([(1, 2), (3,)])在新建mlb的时候可以传入参数classes表示一共有有哪些标签
tensorflow中有关global_step的自增
首先创建变量并初始化很简单,如下所示:
1
global_step=tf.Variable(0, trainable=False)
如果要实现global_step自增,需要在定义优化器的时候传入global_step变量才会自增,否则不会。如下:
1
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_steps)
如果后面部分的global_step=global_steps去掉,global_step的自动加一就会失效。
1
2
3tf.train.Optimizer.minimize(......global_step=None)
tf.train.Optimizer.compute_gradients()
tf.train.Optimizer.apply_gradients(......,global_step=None)上面第一个函数是合并了compute_gradients()与apply_gradients()函数,返回为一个优化更新后的var_list。如果global_step非None,该操作还会为global_step做自增操作。
第二个函数对var_list中的变量计算loss的梯度。该函数为函数minimize()的第一部分,返回一个以元组(gradient, variable)组成的列表
第三个函数将计算出的梯度应用到变量上,是函数minimize()的第二部分,返回一个应用指定的梯度的操作Operation,对global_step做自增操作
Tensorflow的模型保存与恢复
meta文件是我们的计算图结构文件,其他两个分别保存了变量名和变量值
定义保存目录,并作如下判断:
1
2
3
4if not os.path.isdir(ckpt_dir):
os.makedirs(ckpt_dir)
checkpoint_path=os.path.join(ckpt_dir,"model.ckpt")
saver.save(sess,checkpoint_path,global_step=global_steps)这里的global_steps就是我们再定义计算图的时候需要定义的tf.Variable。并且该变量需要用在计算图中的Optimizer中,否则不会自增。
除此之外,想控制保存模型的数目,在新建saver的时候,可以有参数max_to_keep选择。
从检查点恢复模型:
1
2
3
4
5
6
7
8
9
10def create_model(sess,FLAGS):
text_model=Model(FLAGS)
ckpt=tf.train.get_checkpoint_state(FLAGS.ckpt_dir)
if ckpt and ckpt.model_checkpoint_path:
print("restore old model parameters from %s"%ckpt.model_checkpoint_path)
text_model.saver.restore(sess,ckpt.model_checkpoint_path)
else:
print("creating new model")
sess.run(tf.global_variables_iniializer())
return text_model当检查点文件存在的时候,从最新检查点恢复模型参数,否则新建model,并执行global_variables_iniializer。
那么有人会问了,假如我们从检查点恢复模型,就不能再执行初始化操作诸如global_variables_iniializer了,那假如这时候我们往模型中添加了一些其他新变量,那么如何执行变量初始化?
重要的事情说三遍:
从检查点恢复模型,不能再执行初始化操作,否则训练的参数值就没意义了。
从检查点恢复模型,不能再执行初始化操作,否则训练的参数值就没意义了。
从检查点恢复模型,不能再执行初始化操作,否则训练的参数值就没意义了。
tf.global_variables_iniializer与tf.local_variables_iniializer区别
tf.global_variables_initializer()添加节点用于初始化所有的变量(
GraphKeys.VARIABLES)。返回一个初始化所有全局变量的操作(Op)。在你构建完整个模型并在会话中加载模型后,运行这个节点。tf.local_variables_iniializer返回一个初始化所有局部变量的操作(Op)。初始化局部变量(
GraphKeys.LOCAL_VARIABLE)。GraphKeys.LOCAL_VARIABLE中的变量指的是被添加入图中,但是未被储存的变量,比如用来记录某些epoch的数量等。在tensorflow中有一个函数叫做tf.local_variables(),这个函数会返回局部变量(local variables)。 local_variable() 函数会自动的添加新的变量到构造函数或者get_variable()自动地把新的变量添加到 graph collection
GraphKeys.LOCAL_VARIABLES中。这个函数返回这个collection中的内容。为什么要使用变量共享
如何将文件变为可执行脚本,发布出来
利用tf.app.flags.FLAGS,定义一些参数变量和默认值。执行的时候采用tf.app.run(),如果有定义main()函数,直接写tf.app.run()即可。如果没有写main函数,需要在tf.app.run(函数名)写明具体执行什么函数。
Queue读取数据并实现边训练边验证
https://blog.csdn.net/silence1214/article/details/77876552
tensorflow编程中,假如我们使用placeholder的方法,可以很方便的换输入的数据,通过sess.run的feed_dict参数就能选择传入训练数据还是验证数据。但假如我们使用queue来读取数据,换输入数据源就不是这么简单的了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36#使用queue方法得到的数据
train_images, train_label = get_batch_train_data(batch_size)
valid_images, valid_label = get_batch_valid_data(batch_size)
def build_graph(x, y):
#the first layer
w1 = tf......
b1 = tf.....
h1 = tf.nn.relu(tf.matmul(x,w1)+b)...
#the second layer
.....
#the xx layer
......
h = tf.nn.relu(..)
loss = .....
accuracy = ...
train_op = ....
return loss, accuracy, train_op
with tf.Session() as sess:
....
loss, accuracy, train_op = build_graph(train_images, train_label)
coord = tf.train.Coordinator()
enqueue_threads = qr.create_threads(sess, coord=coord, start=True)
try:
for step in xrange(1000000):
if coord.should_stop():
break
_, acc_str, los_str = sess.run([train_op, accuracy, loss])
if step % 100 == 0:
# 这个地方我想加入对验证集合的处理咋办?请看我在代码后面的解释
except Exception, e:
coord.request_stop(e)
finally:
coord.request_stop()
coord.join(threads)一种方法事直接再来一个:loss, accuracy, train_op = build_graph(valid_images, valid_label)。但是,这是建立了一个新的graph,必须重新initialize所有的变量,而不是之前保存的变量的训练结果。
如何解决,改写graph的定义即可?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37def build_graph():
is_training = tf.placeholder(dtype=tf.bool, shape=())
x = tf.cond(is_training, lambda:train_images, lambda:valid_images)
y = tf.cond(is_training, lambda:train_label, lambda:valid_label)
#the first layer
w1 = tf......
b1 = tf.....
h1 = tf.nn.relu(tf.matmul(x,w1)+b)...
#the second layer
.....
#the xx layer
......
h = tf.nn.relu(..)
loss = .....
accuracy = ...
train_op = ....
return loss, accuracy, train_op, is_training
with tf.Session() as sess:
....
loss, accuracy, train_op, is_training = build_graph()
coord = tf.train.Coordinator()
enqueue_threads = qr.create_threads(sess, coord=coord, start=True)
try:
for step in xrange(1000000):
if coord.should_stop():
break
_, acc_str, los_str = sess.run([train_op, accuracy, loss], {is_training :True})
if step % 100 == 0:
valid_acc_str, valid_los_str = sess.run([accuracy, loss], {is_training:False})
except Exception, e:
coord.request_stop(e)
finally:
coord.request_stop()
coord.join(threads)这里有一个问题就是:上面验证部分的程序只有针对一个batch的数据进行验证,如果我们想要针对整个验证集合验证模型怎么办?
法一:设置valid的step为max_valid_step,循环计算max_valid_step多次,但这种情况只能改善上述那种情况,根据设置的max_valid_step不同,有可能会完全遍历验证集,也可能没有将验证集遍历完。
上面这种情况下:在获得valid_batch_data的时候,我们设置string_input_producer的num_epoch为None值,输入队列中的所有文件都被处理后,会将初始化时提供的文件列表的文件全部重新加入队列。这样一来读取valid数据的部分程序肯定不会报OutofRange的Error。因为我们设置的epoch为None
法二:后面再补充
计算loss和准确率
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
注意这里的交叉熵函数不一定要用softmax_cross_entropy_with_logits,多标签分类的时候我们只能选用sigmoid_cross_entropy_with_logits。
1
2
3
4correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))
#求准确率
#tf.cast(correct_prediction, tf.float32) 将布尔型转换为浮点型
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))mnist的多任务多标签问题
对于单标签:
1
2correct_class_op = tf.equal(tf.argmax(network.logits_class, 1), tf.argmax(network.golden_class, 1))
accuracy_class_op = tf.reduce_mean(tf.cast(correct_class_op, tf.float32))多任务学习:类别预测和属性预测。两个任务的loss加起来作为总的loss,然后用于更新网络参数
多标签准确率计算:
1
2
3correct_attrs_op = tf.equal(tf.cast(tf.greater_equal(tf.sigmoid(network.logits_attrs), 0.5), tf.int32), tf.cast(network.golden_attrs, tf.int32))
accuracy_attrs_op = tf.reduce_mean(tf.reduce_min(tf.cast(correct_attrs_op, tf.float32), 1))tf.cast(tf.greater_equal(tf.sigmoid(network.logits_attrs), 0.5), tf.int32)
默认将0.5作为阈值进行0-1标记
tf.reduce_mean(tf.reduce_min(tf.cast(correct_attrs_op, tf.float32), 1))
为什么有一个reduce_min,是因为如果没有完全预测对,如correct_attrs_op为[0,1],此时reduce_min返回为0,表示预测错误。
不管是多标签还是单标签,再计算loss的时候,都是用的logits来计算的(而不是logits经过one_hot来计算的),只是损失函数不同。
多标签分类的评估标准
https://blog.csdn.net/hzhj2007/article/details/79153647
https://blog.csdn.net/wjj5881005/article/details/53389833?utm_source=itdadao&utm_medium=referral
问题在于是不定数量的多标签分类,不知道应该推荐多少个法条。解决方法:(1)选择一个阈值,对于每个法条是否推荐二分类都有一个阈值,但这个阈值并不是0.5就是最好的,并且每个法条的阈值可能不同,所以需要设定每个法条阈值(2)选择一个数值N,我们只截取排在最前面的N个标签。
只有知道每个法条是否真的被预测(或者推荐),我们才能建立confusion_matrix矩阵。这样才能计算P、R、F。而每个标签是否被推荐的概率阈值都是不同的,并且不一定是0.5,那么怎么衡量,可参考ROC-AUC曲线。要么就选择截取的方法,选择预测概率值大的前几个。
汉明损失:表示所有label中错误样本的比例,该值越小表示网络的分类能力越强。
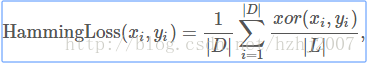
其中:|D|表示样本总数,|L|表示标签总数,xi和yi分别表示预测结果和ground truth。xor表示异或运算。
tf.nn.top_k函数
返回N维Tensor最低维度的前k个最大的值。返回值为两个Tuple,其中values是前k个最大值的Tuple,indices是各个值对应的下标,默认返回结果是从大到小排序的。
其他类似的函数还有tf.nn.in_top_k(),每个样本的预测结果的前k个最大的数里面是否包含targets预测中的标签,一般都是取1,即取预测最大概率的索引与标签对比。
Tensorflow中tensordot与matmul的区别
Tensorflow的softmax函数默认只针对最后一个维度进行,即一个[batch_size,time_step]的矩阵,是对每一行进行softmax,行与行之间相互独立。
跨卡同步BN
https://zhuanlan.zhihu.com/p/40496177