Linux相关操作
快速查看文件前几行:head file.txt。将文件前100行移到另一文件:head -n 100 accu.txt > accu_temp.txt
Linux查看显卡:nvidia-smi
安装配置git
本地与远程仓库的git认证:ssh-keygen
sudo apt-get命令报错dpkg相关错误,info文件重命名
- sudo mv /var/lib/dpkg/info /var/lib/dpkg/info.bak //现将info文件夹更名
- sudo mkdir /var/lib/dpkg/info //再新建一个新的info文件夹
- sudo apt-get update
- sudo apt-get -f install xxx
- sudo mv /var/lib/dpkg/info/* /var/lib/dpkg/info.bak
- sudo rm -rf /var/lib/dpkg/info //把自己新建的info文件夹删掉
- sudo mv /var/lib/dpkg/info.bak /var/lib/dpkg/info //把以前的info文件夹重新改回名字
ssh配置普通账户无密码登陆
先本地ssh-keygen -t rsa(自己的机子上执行)
将id_rsa.pub传到虚拟机,并配置免密码登陆
ssh-copy-id -i ~/.ssh/id_rsa.pub **root**@192.168.1.100,其中root为需要登录到远程机器上的身份,需要替换成需要的用户名。如果要登陆到远程主机的jin,可用如下:
ssh-copy-id -i ~/.ssh/id_rsa.pub **jin**@192.168.1.100
免密码测试登陆的时候,需要写明ssh到哪个账户
ssh root@192.168.1.100或者ssh jin@192.168.1.100
配置slave1 无密码登录 slave2 服务器
1
2
3
4
5
6
7
8在slave1上执行ssh-keygen得到密约
ssh-keygen -t rsa
将公约传到服务器
scp执行
(以下操作在服务器上执行)
将slave1的共约追加到slave2服务器的authorized_keys中,并删除slave1的公钥文件
cat /home/hadoop/id_rsa.pub >> .ssh/authorized_keys
rm /home/hadoop/id_rsa.pubscp传送文件:首先要保证ssh服务开启,所以需要先安装openssh-server
sudo apt-get update
sudo apt-get install openssh-server(可能会遇到dpkg相关错误)
开启服务service sshd start
查看sshd是否启动:ps -e|grep ssh
scp 文件名 root@192.168.68.41:/home/jin/data(这时传到远程主机下的文件是加锁的)
scp 文件名 jin@192.168.68.41:/home/jin/data(这时传到远程主机下的文件是没有加锁的)
这两种方式都是可以的,前提是root和jin都拥有对文件的读取权限。有什么不同,一种在scp的时候通过root连接远程主机,一种通过用户jin连接远程主机。
有时,scp无法传到root用户下,那是因为远程主机没有配置sshd的配置文件PermitRootLogin为yes,当让如果配置了也不行,看是否没有给root账户设置密码:密码设置方法为sudo passwd root
当需要拷贝文件夹(包括文件夹本身):
scp -r /home/wwwroot/www/charts/util root@192.168.1.65:/home/wwwroot/limesurvey_back/scp
需要加一个-r递归
当拷贝文件夹下所有文件,不包括文件夹本身
scp /home/wwwroot/www/charts/util/* root@192.168.1.65:/home/wwwroot/limesurvey_back/scp
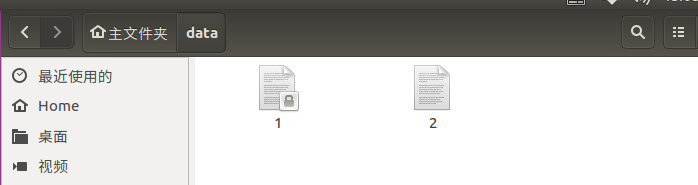
文件1是通过scp 1 root@192.168.68.41:/home/jin/data
文件2是通过scp 2 jin@192.168.68.41:/home/jin/data
区别在于文件是否加锁。查看文件1和2的权限如下:
文件1:-rw-r–r– 1 root root …….
文件2:-rw-rw-r– 1 jin jin ………
经查看:cat /etc/group|grep 组名:用于查找某个用户组
root用户组只有root用户,jin用户组只有jin用户。对于文件1,该文件即使在/home/jin下,jin用户也没有对其更改的权力,如果试图采用vim编辑修改是无法修改的。
Linux查看权限
查看文件权限:ls -l 文件名,查看文件夹权限:ls -d 文件夹名
文件权限修改:
chmod 用户+(-)权限 文件名:其中用户有四个参数可选,u(拥有者)、g(用户组)、o(其他人)、a(所有人)。例如:给文件test的其他用户添加可读权限:chmod o+r test
chmod 权限数字 文件名
例如将test变为文件拥有者可读可写可执行,文件所属组可读可写可执行,其他人可读可执行不可写
chmod 775 test
用户及用户组管理
cat /etc/group:输出用户组,组名称:组密码占位符:组编号:组中用户名列表
cat /etc/group|grep 组名:用于查找某个用户组
cat /etc/passwd:输出所有用户信息,第四个数据为用户组编号
cat /etc/passwd|grep 用户名:用于查找某个用户
groups 用户名:查看该用户所属的用户组有哪些
更改文件拥有者:chown 用户名 文件
更改文件所属群组:chgrp 群组名称 文件
Linux下从普通用户到root用户下copy文件:cp 普通用户下文件 /root用户下路径的文件名
创建user:adduser testuser
给testuser设置密码:passwd testuser
如果当前系统用户处于非testuser下,比如在jin用户中,无法在testuser用户目录下修改删除文件。要想从jin用户复制文件到testuser,只能申请root权限完成
Linux常用命令
ls -a 路径:显示路径下的所以文件,包括隐藏文件
mv:重命名和移动文件
less 文件名:使用方向键移动查看内容
查看命令cp的使用方法:man cp
tab键自动补全
vim编辑
esc进入命令模式,i或者a进入编辑模式
在命令模式下:
x:删除一个字符
u:撤销上一步操作
dd:删除一行
dw:删除一个单词
yy:复制一行
yw:复制一个单词
p:粘贴复制的内容
e:跳到下一个单词
:q:退出,如果文件已经修改,则不能推出
Linux输入密码后又返回登陆界面,可能原因
可能是因为安装了显卡驱动,那进入命令行卸载显卡驱动
Ctrl+Alt+F1进入命令行
sudo service lightdm stop
然后,卸载nvidia显卡驱动。注意此时千万不能重启,重新电脑可能会导致无法进入系统。
sudo apt-get remove nvidia*
卸载显卡驱动
然后Ctrl+Alt+F7返回图形界面
安装Nvidia显卡的官方驱动和系统自带的nouveau驱动冲突。
E: mkinitramfs failure cpio 141 gzip 1
update-initramfs: failed for /boot/initrd.img-3.2.0-33-generic with 1.报上述错:
说明/boot分区满了,如何解决
df -h查看Ubuntu系统使用情况
dpkg –get-selections|grep linux查看已经安装的旧的内核
uname -a查看当前使用内核版本
sudo apt-get remove linux-image- (按两次tab键) 搜索相关linux-image-
sudo apt-get remove linux-image-4.4.0-31-generic删除多余内核
NVIDIA驱动安装
关闭图形界面sudo lightdm stop
init 3启动级别设置为3,已确认完全关闭图形界面
禁用nouveau驱动
下面是正常的命令行操作
注意export PATH即使设置了,在开机过后是没有用的,要设置永久有效,必须加到~/.bashrc
pycharm调出文件函数列表以及变量列表
ALT+7
python中以_开头的函数是protected的,只有该类极其子类才能访问
Linux文件删除
强制递归的删除一个文件夹:rm -r -f 文件夹名字
查看内存和cpu占用情况
free命令
检测tensorflow的能使用设备情况:
1
2from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())查看gpu使用情况
显卡也分为两部分,即显卡跟计算单元,类似与内存跟CPU。
nvidia-smi
Memory-Usage:显卡的显存使用容量跟显卡总的大小
GPU-Util:显卡计算单元使用率。
显卡的使用方式
1
with tf.Session() as sess:
这种方式会把当前机器上所有的显卡的剩余显存基本都占用,注意是机器上所有显卡的剩余显存。因此程序可能只需要一块显卡,但是程序就是这么霸道,我不用其他的显卡,或者我用不了那么多显卡,但是我就是要占用
1
2
3config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction=0.6
with tf.Session(config=config) as sess:其中这种方式跟上面直接使用方式的差异就是,我不占用所有的显存了,例如这样写,我就占有每块显卡的60%。
1
2
3config = tf.ConfigProto()
config.gpu_options.allow_growth=True
with tf.Session(config=config) as sess:上面这种方式是动态申请的,是动态申请显存的,只会申请内存,不会释放内存。而且如果别人的程序把剩余显卡全部占了,就会报错。
第一种因为是全部占用内存,因此只要模型的大小不超过显存的大小,就不会产生显存碎片,影响计算性能。可以说合适部署应用的配置。
第二种和第三种适合多人使用一台服务器的情况,但第二种存在浪费显存的情况,第三种在一定程序上避免了显存的浪费,但极容易出现程序由于申请不到内存导致崩溃的情况指定可以被看见的GPU设备
1
2
3
4
5
6import os
# 默认情况,TF 会占用所有 GPU 的所有内存, 我们可以指定
# 只有 GPU0 和 GPU1 这两块卡被看到,从而达到限制其使用所有GPU的目的
os.environ['CUDA_VISIBLE_DEVICES'] = '0, 1'
# 打印 TF 可用的 GPU
print os.environ['CUDA_VISIBLE_DEVICES']限定使用显存的比例
1
2
3
4
5
6
7
8
9
10
11
12# 在开启对话session前,先创建一个 tf.ConfigProto() 实例对象
# 通过 allow_soft_placement 参数自动将无法放在 GPU 上的操作放回 CPU
gpuConfig = tf.ConfigProto(allow_soft_placement=True)
# 限制一个进程使用 60% 的显存
gpuConfig.gpu_options.per_process_gpu_memory_fraction = 0.6
# 把你的配置部署到session
with tf.Session(config=gpuConfig) as sess:
pass
这样,如果你指定的卡的显存是8000M的话,你这个进程只能用4800M。gpu使用前应声明如何使用,不声明时默认全部霸占
1
2
3
4
5
6
7
8import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0, 1'
gpuConfig = tf.ConfigProto(allow_soft_placement=True)
gpuConfig.gpu_options.allow_growth = True
with tf.Session(config=gpuConfig) as sess:
pass端口查看指令
netstat -an
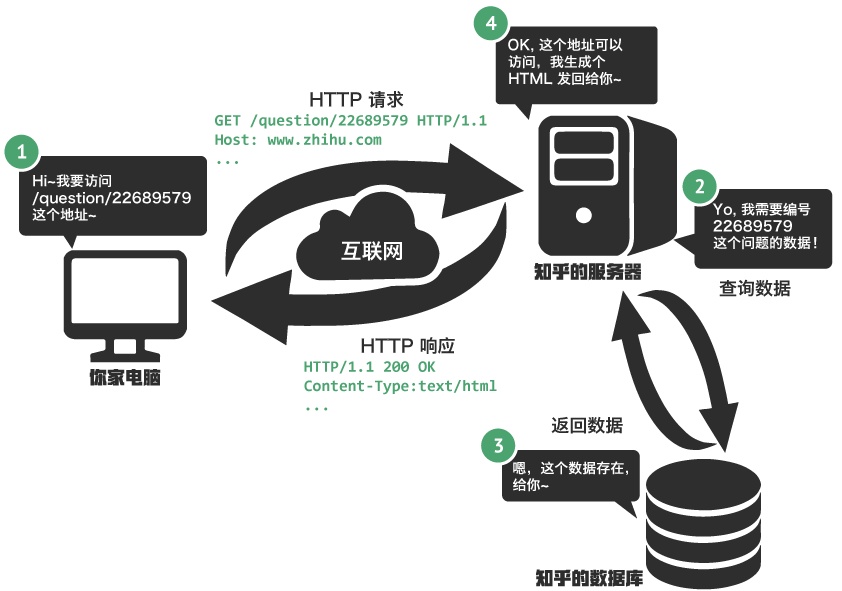
web访问过程