Tensorflow基本编程
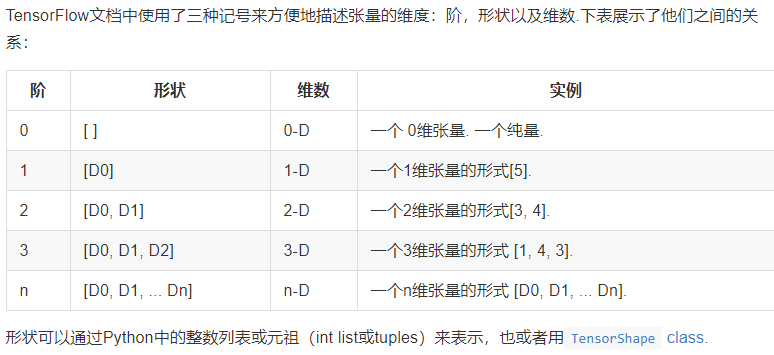
- 张量的阶和形状是不同的概念。一阶张量表示数组,二阶张量表示矩阵。但形状指的是二阶张量的具体形状,比如[3,4]。形状中的None值比如[None, 784],这是一个二阶张量,None表示该维度可以是任何长度。
tensor.get_shape().as_list()
xxx.get_shape()中的xxx的数据类型必须是tensor,且返回的是一个tuple.可以通过xxx.get_shape().as_list()得到一个list。
tf.shape(xxx)
tf.shape(xxx)中xxx数据的类型可以是tensor,list,array
numpy数组的shape获取:
np.shape(数组名)
变量的静态形状与动态形状:
静态(推测)形状:创建一个张量或者由操作推导出一个张量时,初始状态的形状
tf.Tensor.get_shape:获取静态形状
动态(真实)形状:描述原始张量在执行过程中的一种形状
tf.shape(tf.Tensor):如果在运行的时候想知道None到底是多少,只能通过tf.shape(tensor)[0]这种方式来获得
tf.reshape:创建一个具有不同动态形状的新张量
Tensorflow数据读取
feeding供给数据:通过run()函数和eval()函数输入feed_dict参数,可以启动运算过程。设计placeholder节点的唯一目的就是为了提供数据供给feeding的方法。placeholder节点被声明的时候是未被初始化的,不会包含任何数据。如果运行时没有给它供给数据,Tensorflow运行的时候就会报错。
文件读取管线,其相关步骤如下所示:
创建文件名列表
选择是否配置文件名乱序shuffing
选择配置最大迭代次数epoch_limit
创建文件名队列:将文件名列表交给tf.train.string_input_producer()函数,会生成一个先入先出的队列,对应的文件阅读器会需要它来阅读数据。有一个QueueRunner的工作线程专门负责这一生成文件名队列的过程。
QueueRunner的工作线程是独立于文件阅读器的线程,因此乱序和将文件名推入队列这些过程不会阻塞文件阅读器的运行。也就是QueueRunner的运行不会阻塞文件阅读器的运行。
创建针对文件格式的阅读器
记录解析器
可配置的预处理器
样本队列
注意:在调用run函数或者eval函数之前,必须用tf.train.start_queue_runners来将文件名填充到队列。否则,read方法操作将会被阻塞到文件名队列中有值位置。
所以,一个多线程的数据读取往往需要我们创建两个队列,一个是文件名队列string_input_producer,另一个队列tf.train.shuffle_batch()来执行输入样本的训练,评价推理准备
从二进制文件读取固定长度的记录,可以使用
tf.FixedLengthRecordReader的tf.decode_raw操作。decode_raw操作可以将一个字符串转换为一个uint的张量Coordinator:可以用来同时停止多个工作线程并且向那个在等待所有工作线程的程序报告异常。包括方法有should_stop(),request_stop(),join()等。QueueRunner用来协调多个工作线程同时将多个张量推入同意队列中。
QueueRunner会创建一组线程,这些线程可以重复的执行入队操作。这些线程使用同一个Coordinator来处理线程同步终止。通常在训练程序中,会创建一个QueueRunner来运行几个线程,这几个线程处理样本,并将样本推入队列。创建一个Coordinator,让queueRunner来启动这些线程。创建一个训练的循环,并且使用Coordinator来控制QueueRunner的线程的终止。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# Create a queue runner that will run 4 threads in parallel to enqueue
# examples.
qr = tf.train.QueueRunner(queue, [enqueue_op] * 4)
# Launch the graph.
sess = tf.Session()
# Create a coordinator, launch the queue runner threads.
coord = tf.train.Coordinator()
enqueue_threads = qr.create_threads(sess, coord=coord, start=True)
# Run the training loop, controlling termination with the coordinator.
for step in xrange(1000000):
if coord.should_stop():
break
sess.run(train_op)
# When done, ask the threads to stop.
coord.request_stop()
# And wait for them to actually do it.注意join函数是等待被指定的线程终止
coord.join(threads)这里有一个问题是:为什么request_stop会在join函数前面。
不要重新引导主机
tf.train.slice_input_producer、tf.train.batch、tf.train.shuffle_batch、tf.train.shuffle_batch_join
tf.train.slice_input_producer解析
是一个tensor生成器,该函数接受一个tensor列表,然后根据该列表返回一个生成器。按照设定,每次从一个tensor列表中按照顺序或者随机抽取出一个tensor放入列表(注意是一个)。
1
2slice_input_producer(tensor_list, num_epochs=None, shuffle=True, seed=None,
capacity=32, shared_name=None, name=None)其中的第一个参数tensor_list:包含一系列tensor的列表,表中的第一维度的值必须相等,即个数值必须相等。如训练样本X和label Y的第一维度值相等。
dynamic_rnn( )函数
该函数至少需要输入两个数据,一个是padding后的数据,一个是sequence_length记录句子实际长度。再提醒一下,即使用dynamic_rnn( )也需要输入padding过后的数据。返回值如下:
每个time_step的输出值[batch_size,num_step,hidden_size],以及最后一个时间步的状态值(是一个元组(c,h))其中c与h的维度均为[batch_size,hidden_size]
dynamic_rnn()实现的功能可以让不同迭代传入的batch可以是不同长度的数据,但同一迭代一个batch内的数据长度必须是相同的。
不同的计算图Graph如何实现参数共享
会话和计算图的理解
- Tensorflow的程序分为两个阶段,一个是图的构建阶段,在Graph中设置。一个是会话阶段,实际执行训练op的阶段。
- 没有显式声明图,所有操作都是在默认计算图中
-
Tensor和numpy数组的转换
tensor转为numpy数组tensor.eval函数
numpy数组转tensor:tf.convert_to_tensor(numpy数组)
Tensor和变量的区别
Tensor
https://segmentfault.com/a/1190000008793389
https://www.bbsmax.com/A/8Bz8XnaVzx/
tensor用来表示所有的数据,计算图中,操作间传递的数据都是tensor。
如果要获取tensor的实际值,必须要在会话中获取,即需要传递一个session的参数,只在计算图中是无法获取值的
tf.cast( )函数,用在Session之外,是一个op操作
tf.to_int32( )
tensor拼接
tf.concat(values, axis, name='concat'):按照指定的已经存在的轴进行拼接tf.stack(values, axis=0, name='stack'):按照指定的新建的轴进行拼接1
2
3
4
5
6
7t1 = [[1, 2, 3], [4, 5, 6]]
t2 = [[7, 8, 9], [10, 11, 12]]
tf.concat([t1, t2], 0) ==> [[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]]
tf.concat([t1, t2], 1) ==> [[1, 2, 3, 7, 8, 9], [4, 5, 6, 10, 11, 12]]
tf.stack([t1, t2], 0) ==> [[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]]
tf.stack([t1, t2], 1) ==> [[[1, 2, 3], [7, 8, 9]], [[4, 5, 6], [10, 11, 12]]]
tf.stack([t1, t2], 2) ==> [[[1, 7], [2, 8], [3, 9]], [[4, 10], [5, 11], [6, 12]]]
tensor抽取:
tf.slice(input_, begin, size, name=None):按照指定的下标范围抽取连续区域的子集tf.gather(params, indices, validate_indices=None, name=None):按照指定的下标集合从axis=0中抽取子集,适合抽取不连续区域的子集
tf.concat(values,dim,name=’concat’)
在哪个维度拼接,就在哪个维度求和。维度为(3,1)和(3,1)的两个向量,在第一维上连接,就是(6,1);在第二维连接,就是(3,2)
独热编码
https://blog.csdn.net/qq_22812319/article/details/83374125
https://blog.csdn.net/ghy_111/article/details/80362597
tf_onehot()无法对多标记进行编码,因为当你输入一个矩阵为indices时,系统会判定你输入的是一个batch的数据
多线程读取数据的时候,tensor list的第一个维度必须相等
tensor shape为( )表示一个标量,为(?, )表示一个向量,这个向量长度不定
变量
- 变量包含张量(tensor)存放在内存的缓存区。变量需要初始化,模型训练后它们必须存储到磁盘。
- 当创建一个变量的时候,可以将一个张量(哈哈,注意张量或者Tensor)作为初始值传入构造函数Variable。需要指定张量的shape,这个形状会自动变为变量的shape
1 | weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35), |
创建weights和biases都有一个初始的Tensor张量值。这实际上是一个tf.assign的过程,给变量赋实际tensor值。
但是不要以为这样就行了,还需要在session执行一个变量初始化的操作才可以!!!!变量的初始化必须在模型的其它操作运行之前先明确地完成。
1 | # Create two variables. |
- 变量:维护图执行过程中的状态信息,比如模型参数可以用变量来表示。模型参数是状态的一种表示。通常会将一个模型中的参数表示为一组变量。例如,可以将神经网络的权重作为某个变量存储在一个tensor中。
- 变量用于存储网络中的权重矩阵等变量,而Tensor更多的是中间结果
- Variable变量是会显示分配内存空间的,需要初始化操作,由Session管理,可以进行存储、读取、更改等操作。而Const,Zeros创建的Tensor,是记录在Graph中,没有单独的内存空间。
- Tensor可以使用的地方,几乎都可以使用Variable
- 变量的存储与回复
- 如果需要保存和恢复模型变量的不同子集,可以创建任意多个saver对象。同一个变量可以被列入多个saver对象中,只有当saver的restore( )函数运行时,对应变量的值才会改变。
变量共享
http://www.tensorfly.cn/tfdoc/how_tos/variable_scope.html
- tf.variable()无法做到变量共享
定义了一个卷积函数conv_relu(相关参数为weights和bises)。假设我们的卷积神经网络有两层,conv1和conv2,这两层的weights和biases应该是不同的。那么可以用命名域:
1 | def my_image_filter(input_images): |
假设我们现在要用my_image_filter跑两张图片:
1 | result1 = my_image_filter(image1) |
会报错!如果你想共享他们,你需要像下面使用的一样,通过reuse_variables()这个方法来指定.
1 | with tf.variable_scope("image_filters") as scope: |
- tf.variable_scope()
获取当前变量的作用域:tf.get_variable_scope()进行检索,通过调用tf.get_variable_scope().reuse_variables()设置为True .
获取变量作用域并加以使用
1 | with tf.variable_scope("foo") as foo_scope: |