Tensorflow_GPU使用
1.获取会话中相关操作在哪个设备上运行。
获取operations和Tensor被指派到哪个设备上运行,用log_device_placement新建一个session,并设置为True。可以打印出会话中相关操作在哪执行。
1 | # 新建session with log_device_placement并设置为True. |
2.手工指派设备
1 | # 新建一个graph. |
会发现申请常量a和b的操作在cpu上执行,而Tensor相乘在gpu第0块GPU上执行。没有指定设备默认优先第0块GPU。
3.在多GPU系统中使用单一的GPU
如果系统中有多块GPU,那么ID最小的GPU会默认使用。如果想使用其他GPU,可显式声明。
比如指定第二块卡:with tf.device(‘/gpu:2’),假设第二块GPU不存在,那么会报错
为了防止上述问题,可以用如下方法:
1 | # 新建 session with log_device_placement 并设置为 True. |
4.使用多个GPU
多块GPU同时训练:
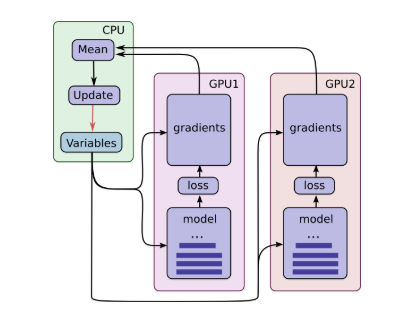
当数据量极其大,每一个GPU会用一批独立的数据计算梯度和估计值。这种设置可以非常有效的将一大批数据分割到各个GPU上。那么问题来了?GPU如何实现参数共享。
首先GPU之间数据的传输很慢,所以可以在CPU上存储和更新所有参数。如此,GPU在处理一批新的数据之前都会先去更新CPU中的参数值。也就是,为了在多个GPU之间共享变量,所有的变量都需要绑定在CPU上,并通过tf.get_variable()访问。