LSTM实现变长文本处理
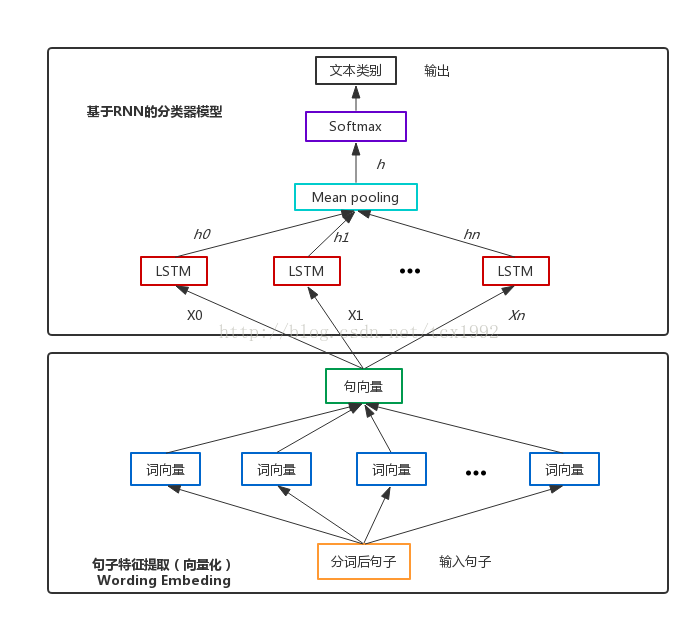

由于喂到模型中是fixed-size tensor(如256*100*50, batch size *sequence
length*embedding size),
RNN需要用mask来maintain序列真实长度,从而在计算loss的时候去除掉padding的部分。Padding和Mask是不一样的。Padding仅仅是补0,如果直接用到LSTM中这些0会参与计算,影响结果。因为LSTM中神经元不仅受当前状态影响,还会受之前状态影响,所以哪怕输入是0仍然可能会有非零输出。而mask是补0后还让LSTM在遇到0的时候溯回到上一个非零的状态,这样就相当于既统一了输入的长度,又告诉了模型每个输入的真实长度,避免这些补的0参与到输入中。



注意:rnn(
)可以利用buckets实现变长rnn的训练,虽然每个graph的RNN的time_step可能不同,但是在不同time_step间网络参数是共享的。所以对于不同的graph1和graph2,即使time_step参数不同,但所有网络参数是可以共享的。
对于dynamic_rnn( )与rnn( )有什么区别:
定义好了一个RNNCell,调用该RNNCell的call函数time_steps次,对应的代码就是:
outputs, state = tf.nn.dynamic_rnn(cell, inputs,
initial_state=initial_state)
得到的outputs就是time_steps步里所有的输出。它的形状为(batch_size, time_steps,
cell.output_size)。state是最后一步的隐状态,它的形状为(batch_size,
n(LSTMStateTuple)),这是因为LSTM的每层状态都是c与h构成的元组。state是整个seq输入完之后的得到的每层的state。如果有n
layer,则state有n个元素,对应每一层的state。
注意区分dynamic_run()与rnn()函数的区别
run()函数的输出.shape为[batch_size,
hidden_units_size],是某一t时刻的输出,对应着t时刻的输入[batch_size,
hidden_units_size]
而dynamic_run()的state强调序列最后一个时刻的输出,注意,是最后一个时刻!!!!!!!!!。而outputs仍然是各个时刻的输出。
其他坑:
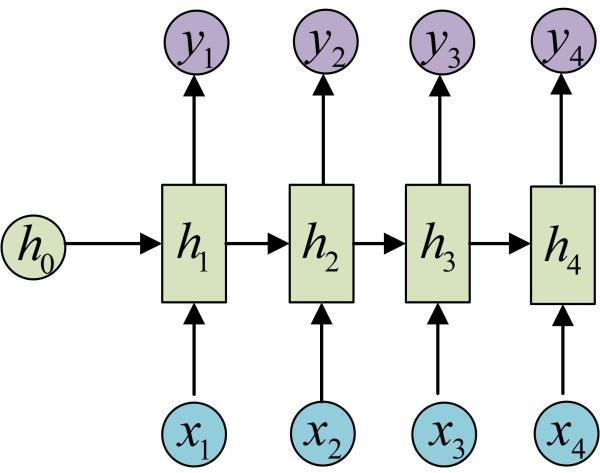
h就对应了BasicRNNCell的state_size。那么,y是不是就对应了BasicRNNCell的output_size呢?答案是否定的。

方法一:
调用 dynamic_rnn() 来让我们构建好的网络运行起来
outputs,state=tf.nn.dynamic_rnn(mlstm_cell,inputs=X,initial_state=init_state,time_major=False)
当 time_major==False 时,
outputs.shape=[batch_size,timestep_size,hidden_size]
State存储各个隐层状态值,包括h_state与c_state【layer_num, 2, batch_size,
hidden_size】
h_state = outputs[:, -1, :]或者h_state = state[-1][1]
最后输出维度是 [batch_size, hidden_size]
写项目遇到的坑:
- 首先是有一个叫做int(
)的参数不能是Variable,比如我想动态调整batch_size时,那么我的batch_size会被设置为变量Variable,在进行
self._initial_state=cell.zero_state(self.batch_size, dtype=tf.float32)报错
这时我们可以用强制类型转换,如下所示:
self._initial_state=cell.zero_state(tf.cast(self.batch_size,tf.int32),
dtype=tf.float32)
- Tf.graph()可以用来建立一个新的图
假如我们用g1=tf.Graph()建立了一个图之后,
With g1.as_default( ):
图内容
上述代码会把g1设置为默认图,当退出上述上下文环境后,系统默认图便不再是g1,而是原来默认的计算图。
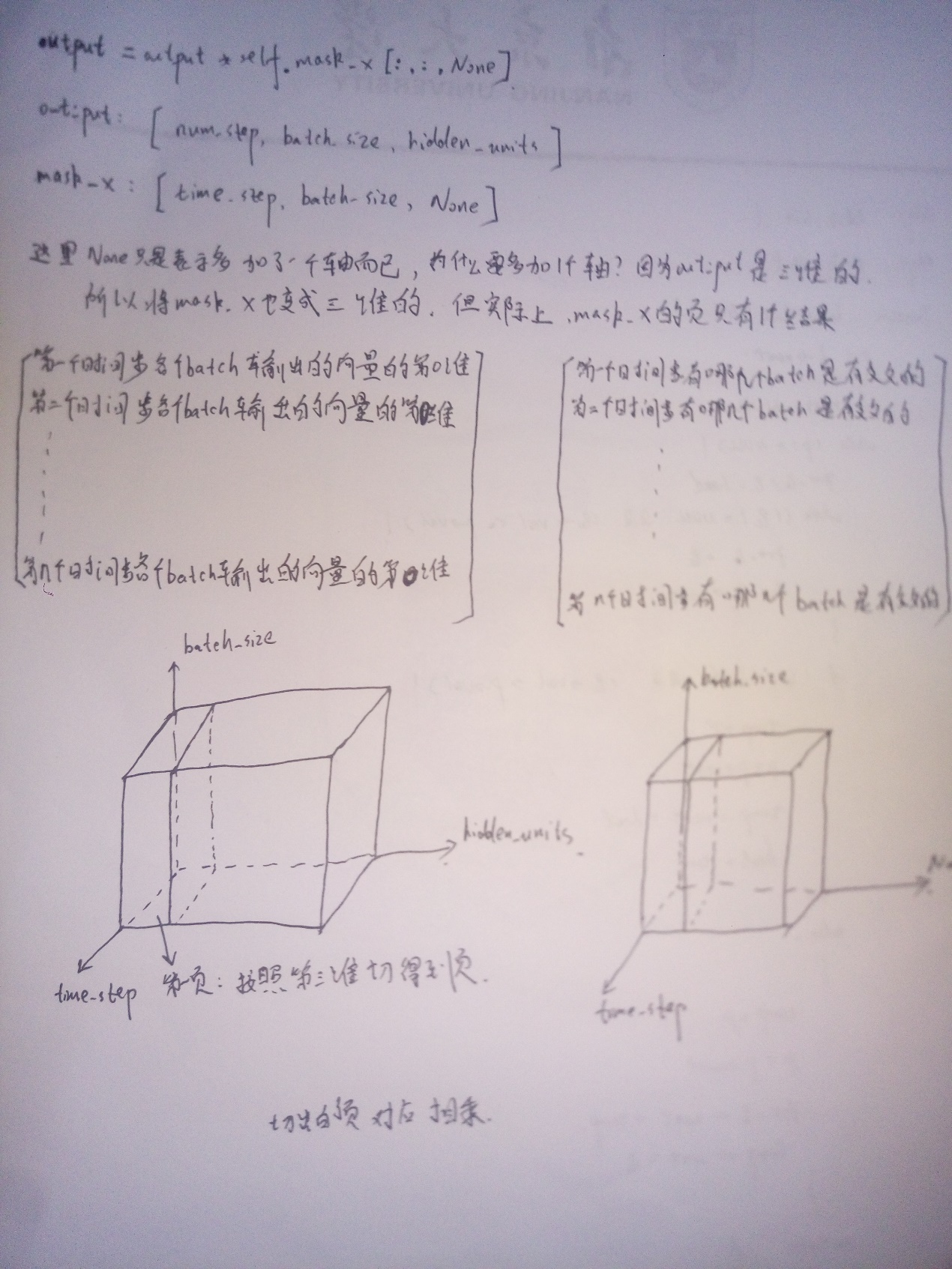
- for time_step in range(num_step):
(cell_output,state)=cell(inputs[:,time_step,:],state)
Out_put.Append(cell_output)
其中输出cell_output这个time_step的输出,维度为[batch_size,
hidden_units],所以最后的out_put维度为[time_step, batch_size, hidden_units]
reduce_sum(),reduce_mean()表示沿着某一维度压扁并进行运算
Tensorboard到底指到哪个目录结构由tf.summary.FileWriter(
)决定,该函数的路径参数即是tensorboard的指定路径三维矩阵相乘,为对应页相乘
C:\Users\jzeng\Documents\Tencent
Files\1534357193\FileRecv\MobileFile\P80425-195942.jpg
循环神经网络处理变长文本
有多种方法:比如dynamic_rnn( )或者建立mask_x矩阵
在使用RNN的时候,需要指定num_step,也就是Tensorflow的roll
step步数,但对于变长的文本而言,指定num_step不可避免的需要执行padding操作,用mask方法先自动padding,再对padding的内容进行删除,需要我们定义mask矩阵。除了mask方法,tensorflow还提供了一种更为优雅的dynamic_rnn的方法
