Attention机制
本章问题:
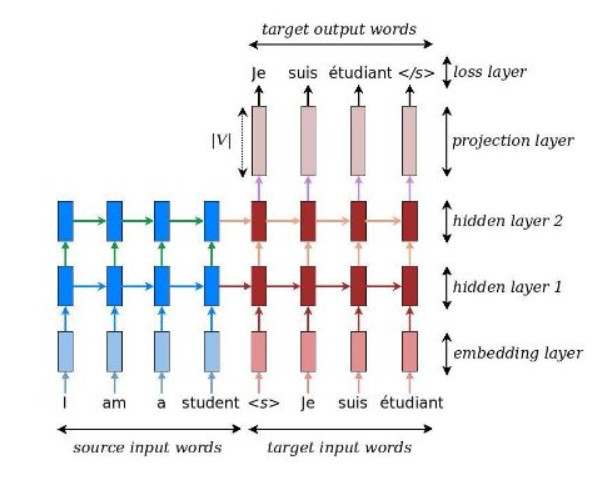
seq2seq解码器端输出层需要一层projection layer层,映射到vocab的维度
seq2seq的dynamic_decode的输出outputs.rnn_output维度必须搞清楚。
seq2seq的Helper对象作用
Attention如何用tensorflow实现
如何实现multiAttention
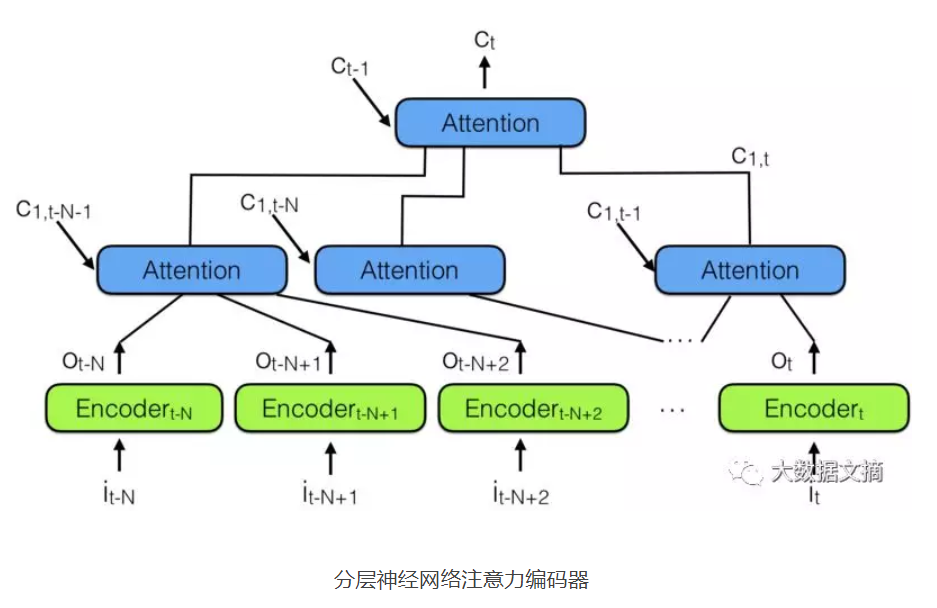
分层attention
我们所用的seq2seq模型



dynamic_rnn怎么处理变长的句子:会通过参数source_sequence_length告诉dynamic_rnn输入的一批数据的长度,dynamic_rnn该函数在超过序列长度的time_step输出为0,状态保持上一个时间步的状态。
具体用法如下所示:

我们再定义解码器的时候需要定义一个helper的对象,再用decoder_cell和helper定义decoder,运行decoder即可用dynamic_decode(decoder……)。dynamic_decode返回的参数(final_outputs,
final_state, final_sequence_lengths),也就是最后时间步的输出和状态。

Logits维度[max_decoder_time, batch_size, vocab_size]
对于TrainingHelper函数,定义了解码器的输出logits采用的获取id的采样方法:
第一个参数是潜入后的输入, time_major=True时,inputs的shape为[sequence_length,
batch_size, embedding_size]
sequence_length:指的是当前batch中每个序列的长度(self._batch_size =
array_ops.size(sequence_length))。
Helper.py文件



具体是如何计算的:将解码器的标准输出标签decoder_outputs[max_decoder_time,
batch_size]与解码器预测的logits[max_decoder_time, batch_size,
vocab_size]做交叉熵,至于这里为什么要除以batch_size其实我也不是很懂。
需要指出的是我们用 loss 除了个 batch_size,所以我们的超参数对 batch_size
来讲是“不变的”(不相关的)。有些人用 loss 除以 (batch_size *
num_time_steps),这样做会减少在短句子上产生的错误。
Seq2seq翻译推理


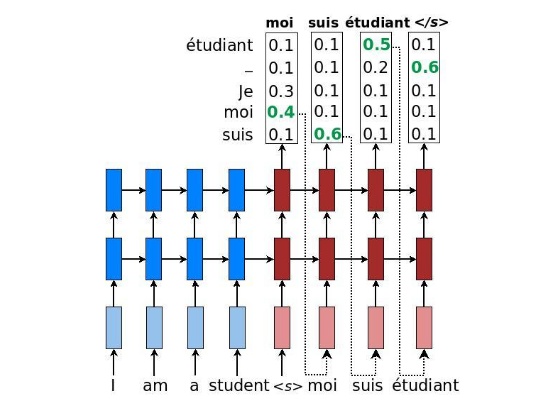
推理与训练的区别在于步骤
3。推理不总是馈送作为输入的正确目标词,而是使用被模型预测的单词,因为我们推理的时候没办法事先知道正确解码的句子。
分层注意力机制

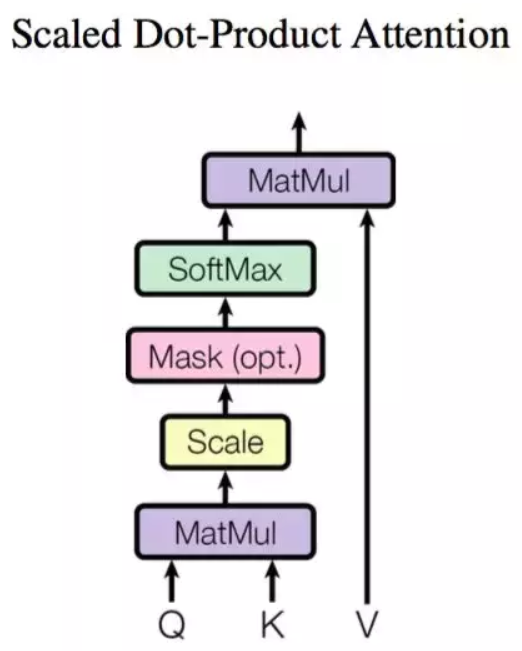
点乘注意力
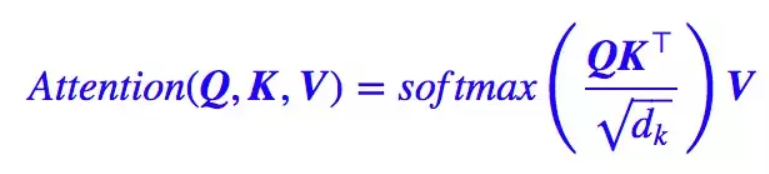

重要的事情说三遍:
我们attention的对象是谁,就要对该对象进行加权求和。假如我们attention的是编码器各个时间步的状态,就要对各个时间步的状态向量加权求和。
我们attention的对象是谁,就要对该对象进行加权求和。假如我们attention的是编码器各个时间步的状态,就要对各个时间步的状态向量加权求和。
我们attention的对象是谁,就要对该对象进行加权求和。假如我们attention的是编码器各个时间步的状态,就要对各个时间步的状态向量加权求和。
这里我们简单解释一下,这里我们把矩阵V想象成一个列向量比较好,每个元素表示一个状态向量:
QKT表示这样的一个矩阵(n*m):第一行是query的第一个time_step状态向量(也就是第一个词)与编码器所有time_step的状态计算出的权重向量(编码器有多长,权重就有多少个),用该权重向量乘以V向量就得到了解码器第一个time_step的attention向量。
那如果是selfAttetion呢?Q、K、V可能同时是编码器的状态矩阵或者解码器的状态矩阵。那么QKT矩阵的第一行是编码器第一个时间步与所有时间步的相似度权重向量,该权重向量和V向量加权求和得到新的向量,其他同理。最后我们把n*d_k的序列Q编码成新的n*d_k的序列。
多头注意力
Multi-head Attention
允许模型联合关注不同位置的不同表征子空间信息,我们可以理解为在参数不共享的情况下,多次执行点乘注意力
在原论文和实现中,研究者使用了 h=8 个并行点乘注意力层而完成 Multi-head
Attention。对于每一个注意力层,原论文使用的维度是
d_k=d_v=d_model/h=64。由于每一个并行注意力层的维度降低,总的计算成本和单个点乘注意力在全维度上的成本非常相近。

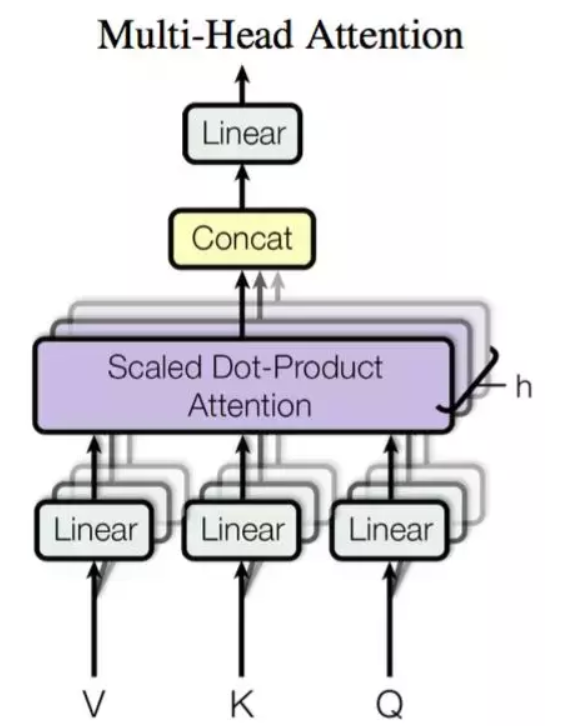
它其实就是多个点乘注意力并行地处理并最后将结果拼接在一起。一般而言,我们可以对三个输入矩阵
Q、V、K 分别进行 h 个不同的线性变换,然后分别将它们投入 h
个点乘注意力函数并拼接所有的输出结果。
首先我们会取 query 的第一个维度作为批量样本数,然后再实现多个线性变换将 d_model
维的词嵌入向量压缩到 d_k
维的隐藏向量,变换后的矩阵将作为点乘注意力的输入。点乘注意力输出的矩阵将在最后一个维度拼接,即
8 个 n×64 维的矩阵拼接为 n×512 维的大矩阵,其中 n
为批量数。这样我们就将输出向量恢复为与词嵌入向量相等的维度。



如何实现多头的attention:

位置Embedding




一般的,这种纯selfAttention机制训练一个文本分类或者机器翻译模型,效果应该都还不错,但是用来训练一个序列标注模型(分词、实体识别等),效果就不怎么好了。原因是机器翻译并不特别强调语序,因此PositionEmbedding所带来的位置信息以及足够了,此外翻译任务的评测指标BLUE也并不特别强调语序。
实例分析:
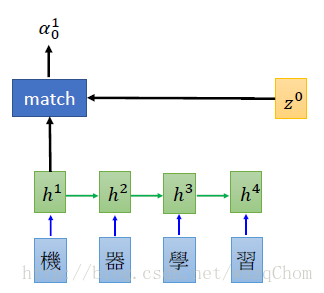


参数学习:
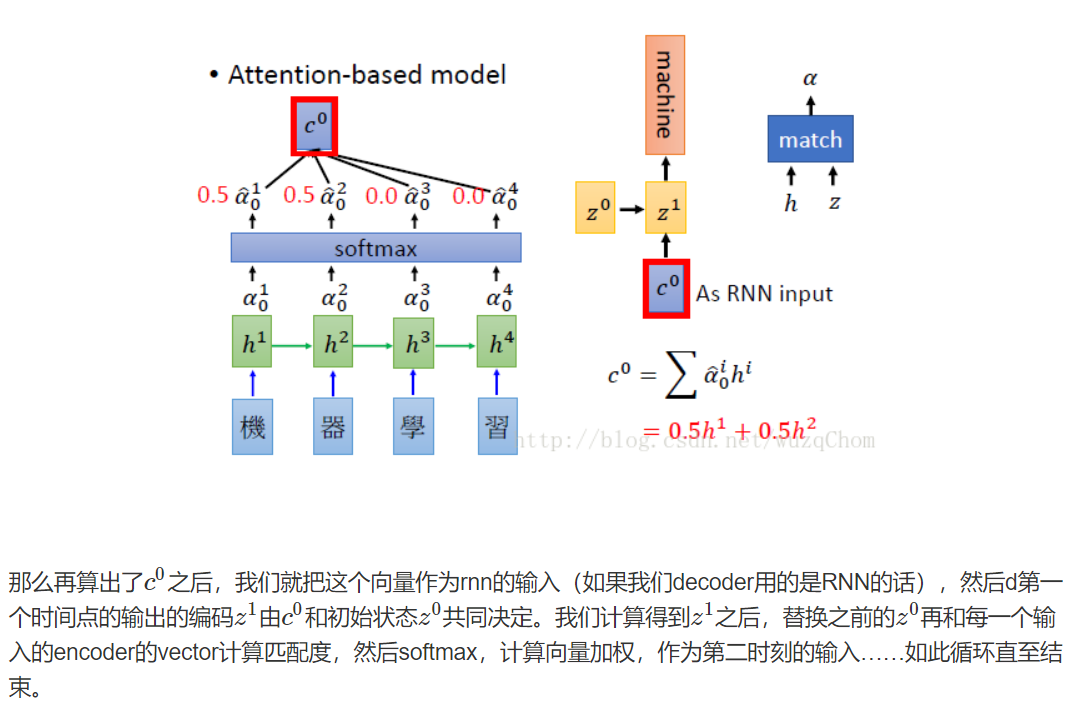
注意力机制的一个很好副产品是源语句和目标语句之间的一个易于可视化的对齐矩阵

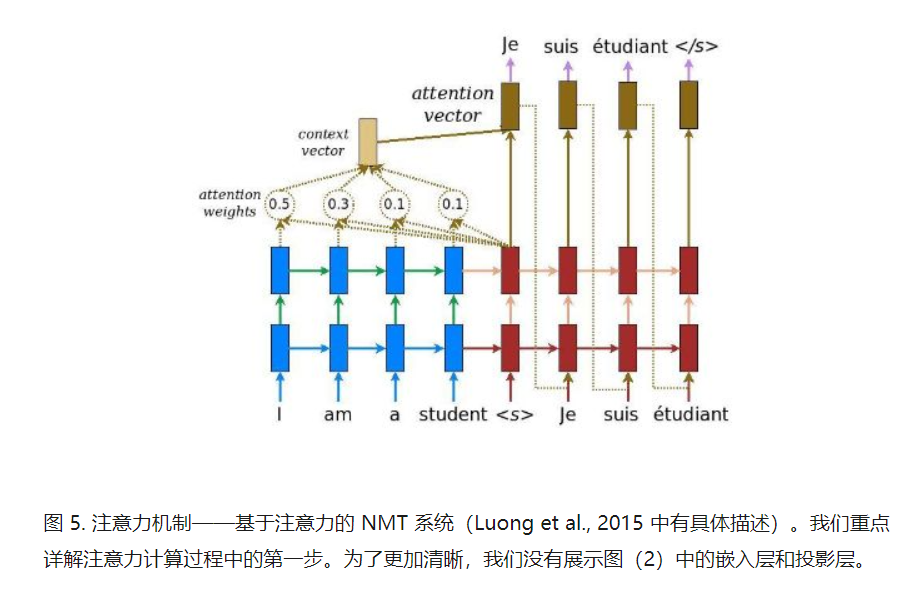
Attention中涉及的矩阵运算
当前目标隐蔽状态和所有源状态(source
state)进行比较,以导出权重(weight)。基于注意力权重,我们计算了一个背景向量(context
vector),作为源状态的平均权值。
将背景向量与当前目标隐蔽态进行结合以生成最终的注意力向量。
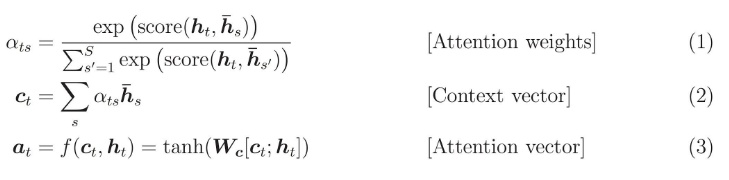
注意力向量是怎么生成的?生成的上下文向量(编码器隐状态的加权求和)与当前步解码器的状态拼接输入一个tanh激活函数的全连接神经网,最后再通过softmax分类即可。
Score函数也可以用以下方法:
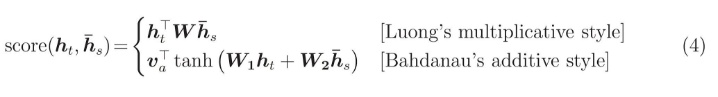
第一种是两个向量简单相乘(一个行向量乘以一个列向量是一个数,也可以理解为相似度),另一种是通过一层神经网络实现



这里的memory就是我们的attention_states


首先要有一个query向量,和一段key向量,这里query可以理解为一个包含比较多信息的全局向量,这段key向量就是我们想要attention的对象,attention操作就是利用这个query对所有key向量进行加权求和。
谷歌Transformer的整体框架
Transformer
的整体架构也采用了这种编码器-解码器的框架,它使用了多层自注意力机制和层级归一化,编码器和解码器都会使用全连接层和残差连接。Transformer
的整体结构如下图所示:
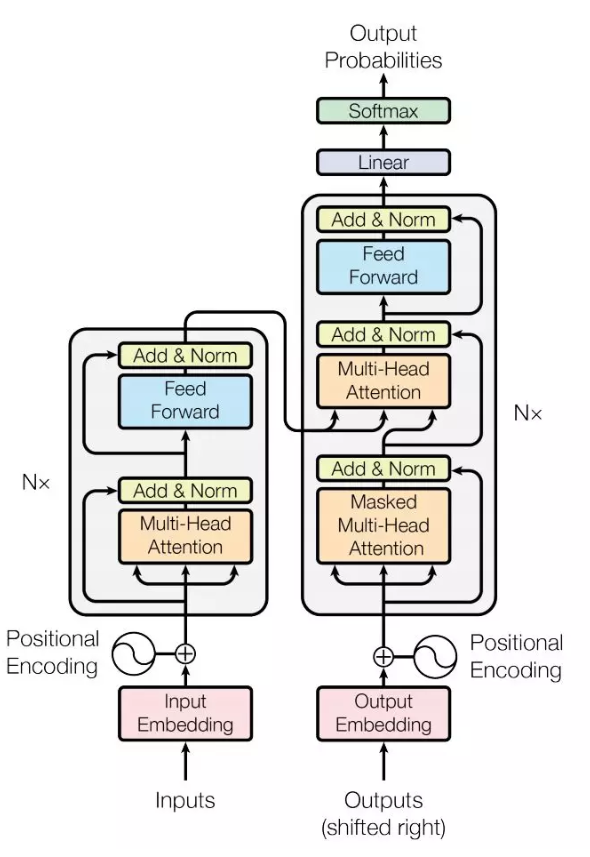

编码器由相同的 6
个模块堆叠而成,每一个模块都有两个子层级构成。其中第一个子层级是 Multi-Head
自注意机制,其中自注意力表示输入和输出序列都是同一条。第二个子层级采用了全连接网络,主要作用在于注意子层级的特征。此外,每一个子层级都会添加一个残差连接和层级归一化。

附加:
