LSTMCell参数解释
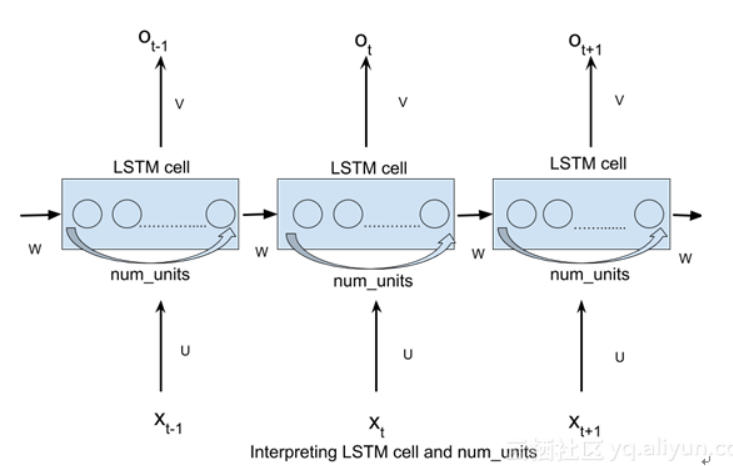
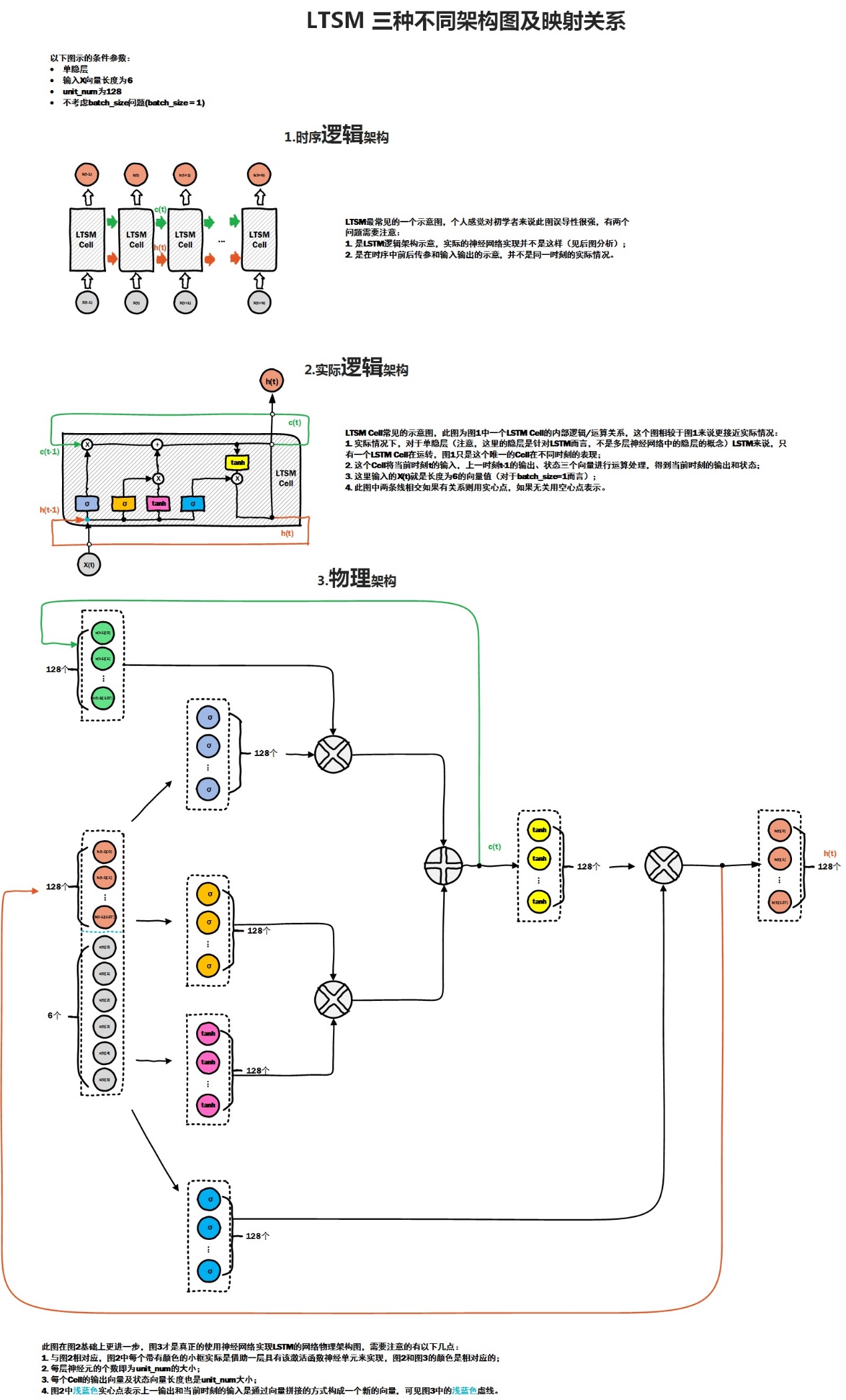
LSTM输入:输入参数batch_size,time_step,输入词向量维度,另外还需要定义隐层神经元个数num_units。
对于每个时间步:输入数据维度为【batch_size*输入词向量维度】,矩阵W维度为【输入词向量维度即输入层单元,num_units】,隐层输出数据【batch_size*
num_units】,矩阵U的维度为【num_units,num_units】。
每个时间步都是这样的,所以隐层在所有时间步乘上权重后,形成的Tensor为[time_step,batch_size,num_units]或者[batch_size,time_step,num_units]



num_units也可以解释为前馈神经网络隐藏层的类比。前馈神经网络隐层中的节点num_units数目等于LSTM网络每个时间步长的LSTM单元的数量。以下图片应该可以帮助你理解:t-1时刻隐层到下一个隐层的状态tensor是一个向量,向量的维度是隐层神经元的个数。每个num_units,LSTM网络都可以将它看作是一个标准的LSTM单元。(注意:
num_units和time_step的意思是不一样的)
对于我们的MNIST图像的情况,我们有大小为28X28的图像。它们可以被推断为具有28行28像素的图像。我们将通过28个时间步骤展开我们的网络,使得在每个时间步长,我们可以输入一行28像素(input_size),从而通过28个时间步长输入完整的图像。如果我们提供batch_size图像的数量,每个时间步长将提供相应的batch_size图像行(比如batch_size为5,则每个时间步应该输入5图像行到网络中),如下图:
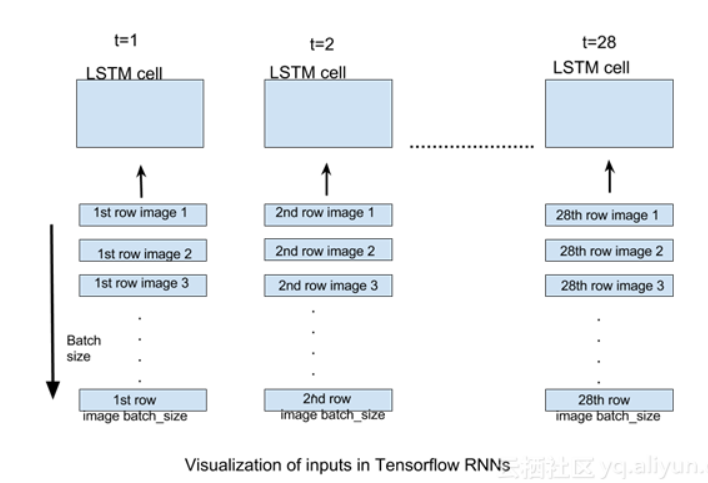
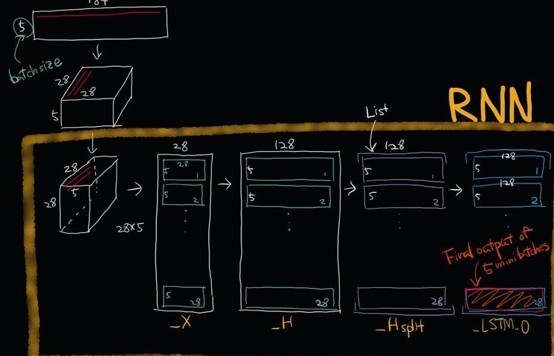
生成的输出是一张列表L,列表的每个元素是张量[batch_size,n_hidden]。列表L的长度是网络展开的时间步长数,即每个时间步长输出一个张量。在这个实现中,我们将只关注最后时间的输出,当图像的所有行被提供给RNN时,即在最后时间步长将产生预测。
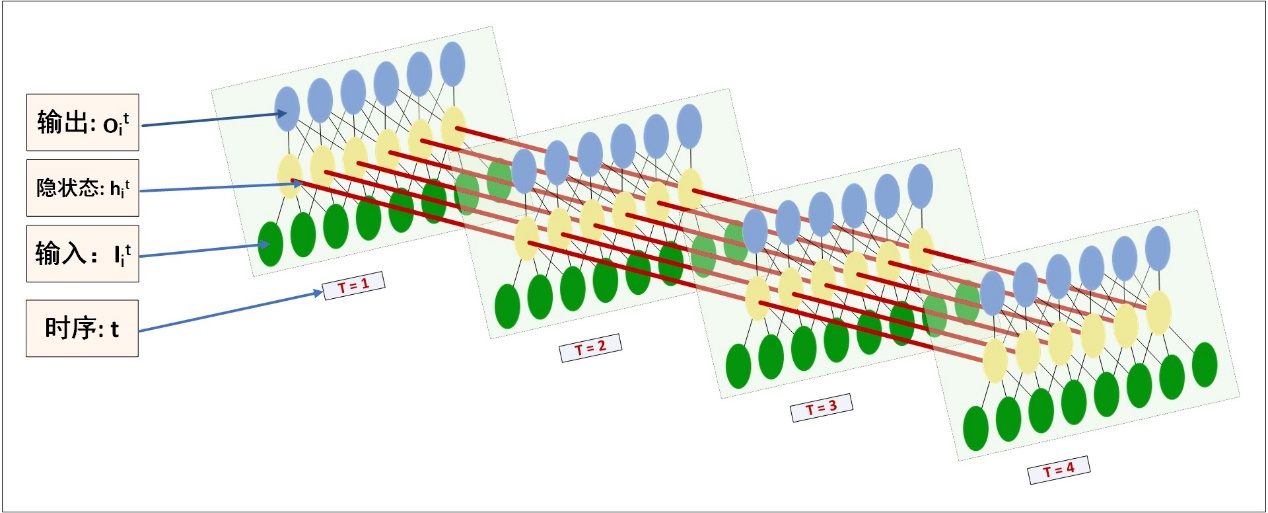
过程示意图
https://www.zhihu.com/question/41949741
RNN的状态是通过一个向量来表示,这个向量的维度也称为RNN隐藏层的大小。
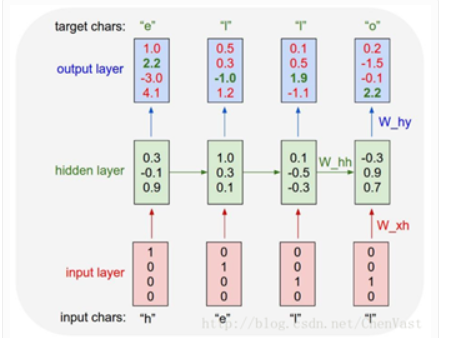
下图是实际的沿时间展开的网络图:
再结合一个操作实例说明。如果我有一条长文本,我给句子事先分割好句子,并且进行tokenize,
dictionarize,接着再由look up table
查找到embedding,将token由embedding表示,再对应到上图的输入。具体过程见如上网址!!!!!
将词用向量表示,那么每句话可以看作是一个矩阵。每一列代表一个词向量,词向量维度自行确定,矩阵列数固定为time_step
length。假设一个RNN的time_step为L,则上述矩阵的列数为L。一次RNN的run只处理一条Sentence,每个sentence的每个token的embeding对应了每个时序t的输入。一次RNN的run,连续的将整个sentence处理完。
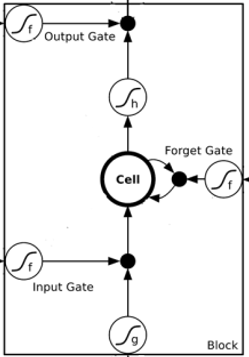
LSTM内部的神经网络
门实际上就是一层全连接层,它的输入是一个向量,输出是一个0到1之间的实数向量。门的激活函数为sigmoid函数,计算当前输入的单元状态c’t所用的激活函数是tanh函数
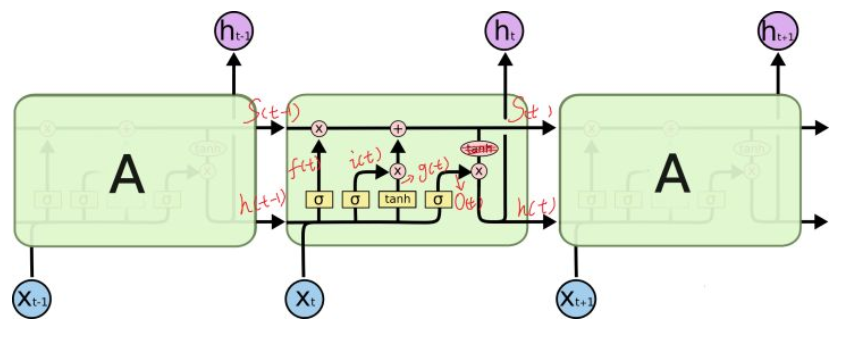
可以看到中间的 cell 里面有四个黄色小框,每一个小黄框代表一个前馈网络层,
num_units就是这个层的隐藏神经元个数。其中1、2、4的激活函数是
sigmoid,第三个的激活函数是 tanh。cell
的权重是共享的,这是什么意思呢?这是指这张图片上有三个绿色的大框,代表三个 cell
对吧,但是实际上,它只是代表了一个 cell
在不同时序时候的状态,所有的数据只会通过一个 cell,然后不断更新它的权重。
注意:num_units定义的是一个门的隐层神经元个数,比如遗忘门,输入维度为h(t-1)拼接x(t),隐层为num_units,所以遗忘门的参数为num_units*(h(t-1)+
x(t))。其他两个门和输入激活的分析同上,所以LSTMcell参数个数为4*
num_units*(h(t-1)+x(t))。中间层的参数就是这样,不过还要加上输出的时候的激活函数的参数,假设是10个类的话,就是128*10的
W 参数和10个bias 参数(注意,输出层图中没有画出)
下面从三个角度分析LSTM中的网络:
3.1 以Mnist为例分析RNN
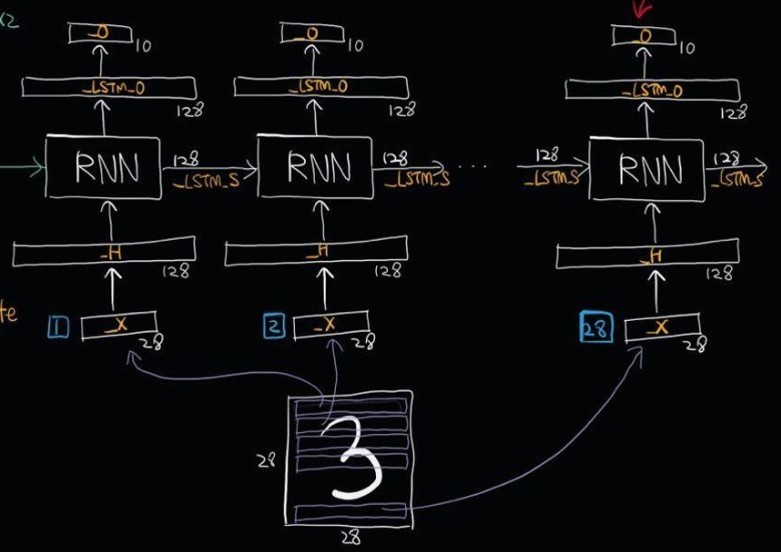
将一个28*28的mnist数据集图片按行送入RNN,从而实现手写体数字识别。这里按行切了28行(一般按列来做切片,_H为128
是因为RNN单元有128个LSTM Cell,所以需要一次线性转换)
Batchsize定义了一个batch有多少张图片,time_step定义了RNN的时间步数(这里是28行),diminput定义了输入数据的维度(这里是28,每行向量维度为28)。
3.2 案例分析
上一时刻与当前时刻输入拼接,维度和为3,所以输入层神经元个数为3。被RNNcell的两个隐层神经元处理,输出状态h1到下一个时刻,并在当前时刻产生输出y0
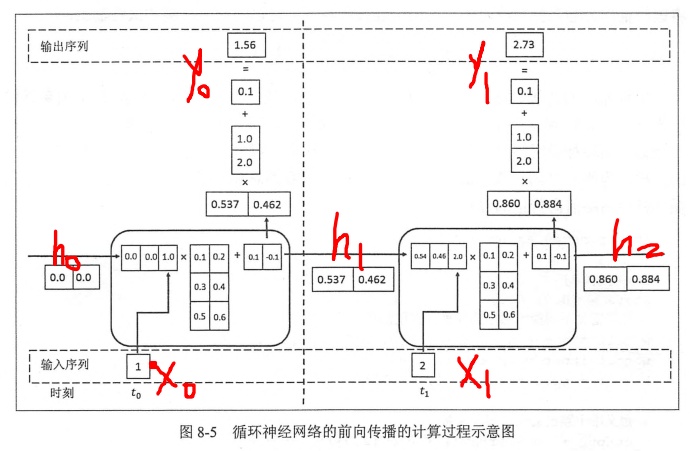
以下的分析参考博客:https://blog.csdn.net/m0_37306360/article/details/75307023
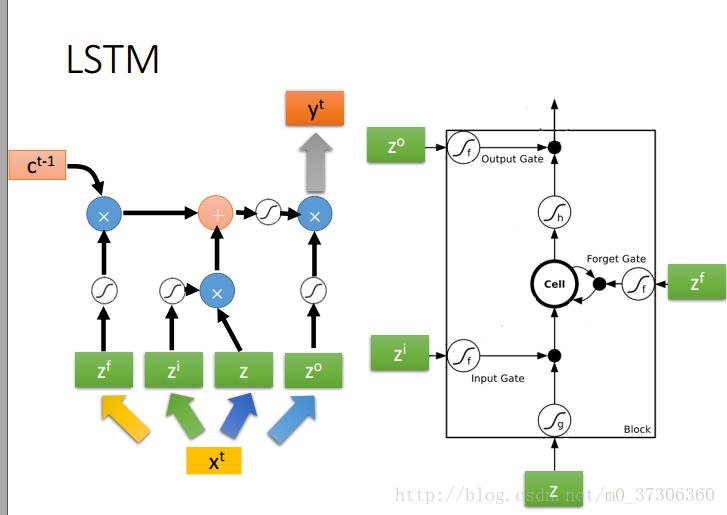
这个图已经不陌生了吧,xt是t时刻的输入向量,z,zt,zo,zi分别为LSTM四个输入,那他们是怎么来的?xt向量乘以不同的权重矩阵构成了z,zt,zo,zi,然后z,zt,zo,zi分别作为LSTM的四个不同输入,这个时候问题又来了,为什么只有一个LSTM?别急,看下图,其实,每一个LSTM的输入都是一维的,所以你有多少维,就应该有多少LSTM。
若xt向量乘以不同的权重矩阵构成的z,zt,zo,zi不是一维的(num_units不为1),那么就可能有num_units个LSTM单元,如下:
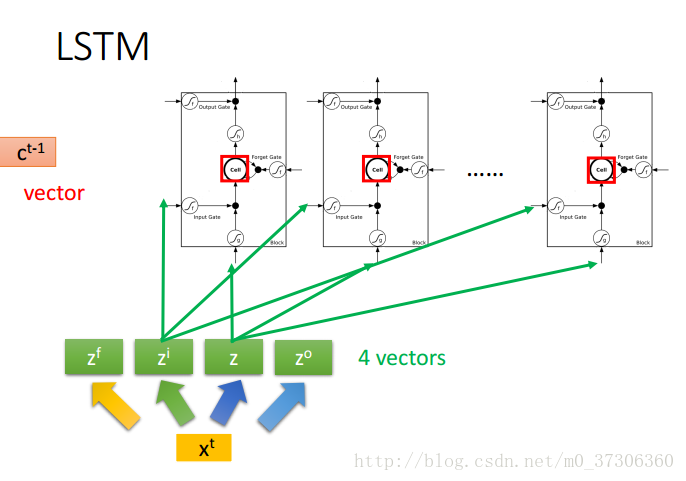
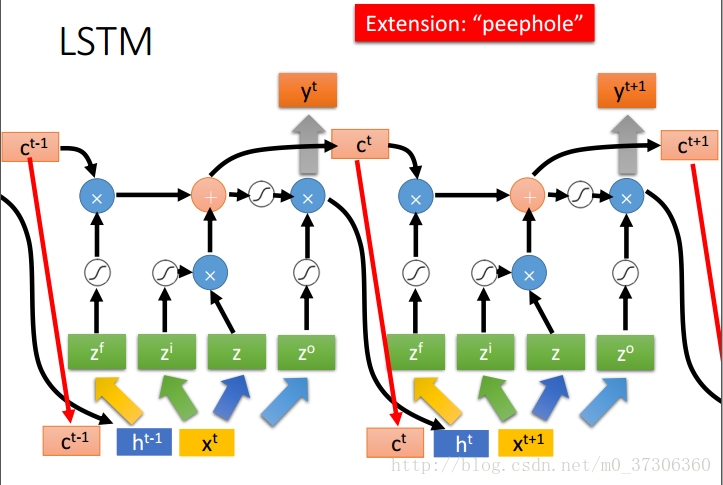
但LSTM计算时采用向量化,所以为了简单,我们经常以向量化的方式画成一个简图如下:
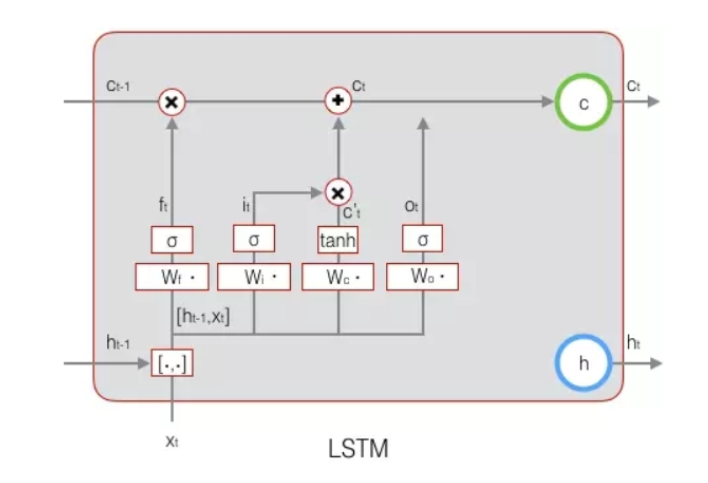
因为上图方框内包含了向量运算,实际上的LSTMBlock只有如下图的激活函数作用(没有向量运算),这就是向量式与非向向量式LSTM概念图的区别。
每一个记忆单元的值以及上一个时刻的输出会和xt一起来乘以不同的matrix生成此时刻的z,zt,zo,zi,所以就变成了这样:
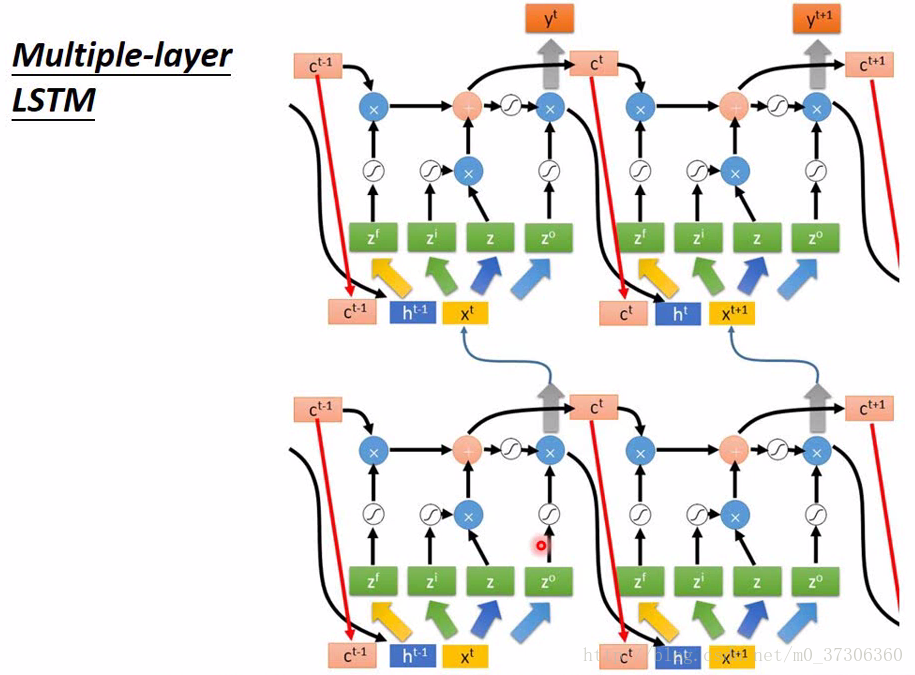
上面考虑的仅仅是只有一个隐藏层的,但是很多时候隐层往往是多层甚至是深层的,所以你经常看到的应该是这样的
其他参考博客:http://brightliao.me/2016/12/11/dl-workshop-rnn-and-lstm-1/
附加:
Tensorflow编程注意:变量初始化
如果你在 Tensorflow
中设定了变量,那么初始化变量是最重要的!!所以定义了变量以后,
一定要定义init=tf.global_variables_initializer()。到这里变量还是没有被激活,需要再在 sess 里, sess.run(init) ,
激活 init 这一步
with tf.Session() as sess:
sess.run(init)