最近在研究关系抽取,由于人工标注太麻烦,所以想用远程监督生成更多数据。那么就必须找相对准确的关系模式,比如在已有知识图谱关系三元组,这就涉及到知识图谱三元组抽取了。其实,也可以人工定制少量的准确的关系三元组作为远程监督的种子,不过太麻烦了。
在线查看(以wikidata知识图谱为例)
得到和用户输入有关的实体id
实体信息获取
https://www.wikidata.org/w/api.php?action=wbgetentities&ids=Q495015&format=json&languages=en
entity顶级字段:
id: 实体id。
type: 实体类型。
labels: 不同语言描述的实体标签。
descriptions: 不同语言的实体描述。
aliases: 不同语言描述的实体别名。
claims: 以属性分组的实体声明(claims)或者陈述(statements)。
sitelinks: 各种网站上关于此实体的描述。
lastrevid: 当前json文件的版本。
modified: 当前json文件的发布日期。
而entity中的具体数据被称为claim,一个entity可以有许多
claim.每个claim总是与一个属性(property)关联,并且在一个实体中可以有多条claim与同一property关联。从结果可以看出,P109属性的结构
[ { },{ },……],是一个Json数组,对应到维基数据上:
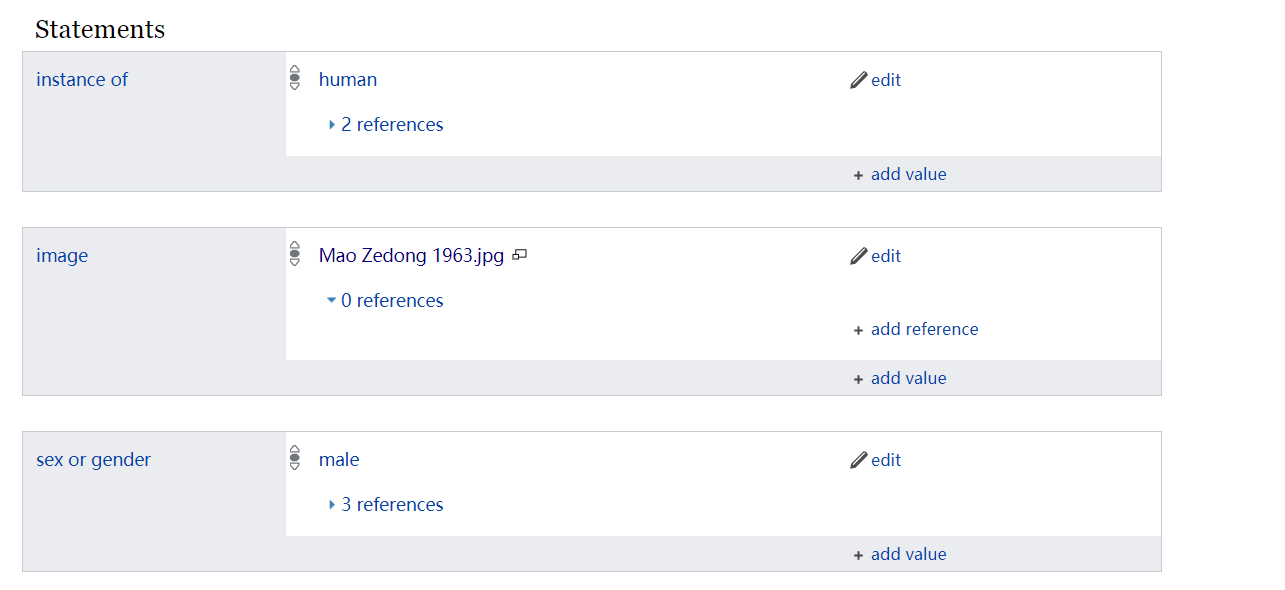
左侧栏目定义了属性,右侧是与该属性关联的claims,可以有一个,也可以有多个。
id: 识别码,只能保证当前数据库中唯一,不包含其他信息。
type: claim的类型,目前只有statement和claim两种。
mainsnak:
如果claim含有type值,那么它具有mainsnak字段包含与property相关的主体信息。注意:mainsnak中的datavalue也可以为其它关联实体(提供实体id)
rank: 表示claim是否应该显示在查询结果中,为preferred, normal 或者 deprecated.
qualifiers:
修饰信息,一般为主体信息的上下文信息,每一条都与一个属性(property)关联。
references: 如果claim是statement,那么会有一个参考资料的列表。
属性详情查看
参考网站:https://www.ibm.com/developerworks/cn/java/j-sparql/\#fig1
解析RDF数据得到语义Net
RDF图模式解析
主题是节点,谓词是圆弧,值在圆弧的另一边
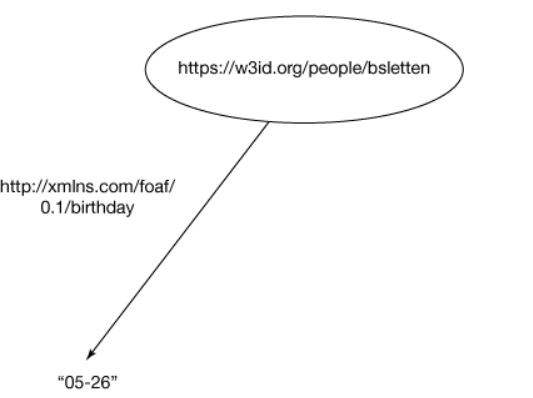
需要将我的生日发布为一个机器可以处理的事实,可以使用一个称为 N-Triples
的简单的 RDF
序列化,将语句存储到一个文件中。采用这种格式时,每行都有一个用句点终止的事实如下:
\https://w3id.org/people/bsletten\\http://xmlns.com/foaf/0.1/birthday\
“05-26”
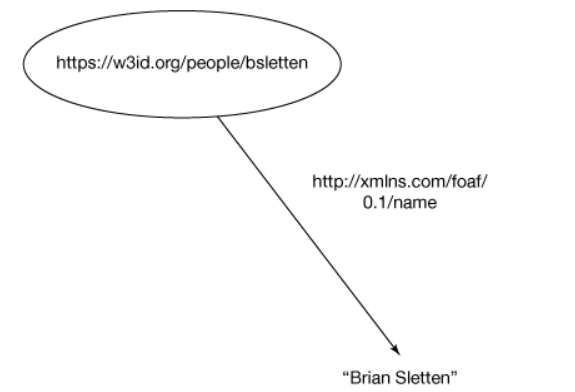
\https://w3id.org/people/bsletten\ \http://xmlns.com/foaf/0.1/name\
“Brian Sletten”
不管这两个事实是存储在同一个文件中,还是存储在两个不同的文件中,如果它们被读入相同的模型中,那么属性和值将会针对主题进行累积(如图
3 所示),因为这两个语句引用了使用相同标示符的同一个主题。
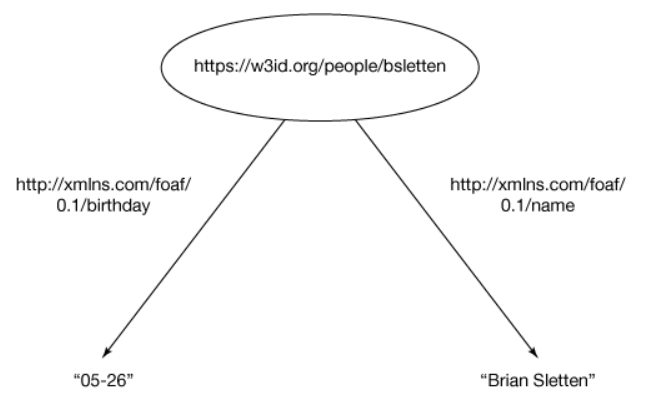
\https://w3id.org/people/bsletten\ \http://xmlns.com/foaf/0.1/birthday\
“05-26”
\https://w3id.org/people/bsletten\ \http://xmlns.com/foaf/0.1/name\
“Brian Sletten”
如何定义实例所属关系:需要一个特殊的谓词来表明资源是某个类的一个实例。RDF
为这种类型的关系提供了一个术语:http://www.w3.org/1999/02/22-rdf-syntax-ns\#type。这种类型的语句具有与您目前为止看到的属性关系不同的语义,但表达方式是相同的:
\https://w3id.org/people/bsletten\\http://www.w3.org/1999/02/22-rdf-syntax-ns\#type\ \http://xmlns.com/foaf/0.1/Person\
.
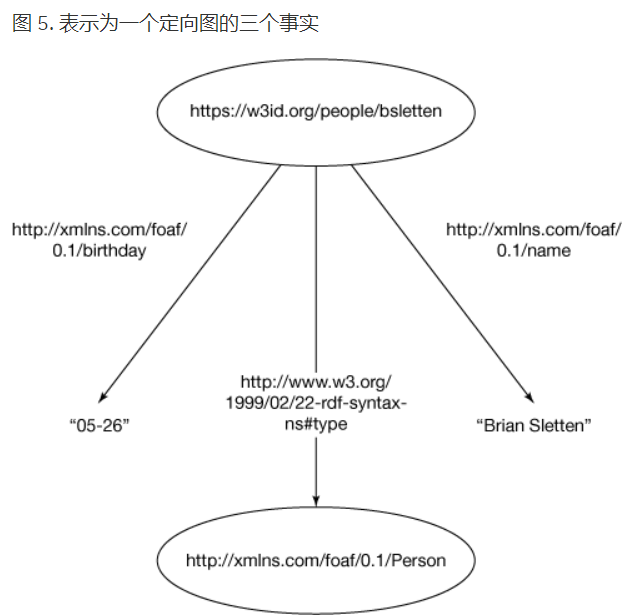
所以,最后的N-triples描述文件如:
\https://w3id.org/people/bsletten\ \http://xmlns.com/foaf/0.1/birthday\
“05-26”
\https://w3id.org/people/bsletten\ \http://xmlns.com/foaf/0.1/name\
“Brian Sletten”
\https://w3id.org/people/bsletten\\http://www.w3.org/1999/02/22-rdf-syntax-ns\#type\ \http://xmlns.com/foaf/0.1/Person\
应用
数据如下所示:

基础查询:sparql –query query.rq –data basic.nt
在 RDF
中,节点转换为主语实体,连接到属性的圆弧将它们连接到图形中的其他节点。
找到指定图形模式中的主语:主语通过uri指定
SELECT ?p ?o WHERE { \https://w3id.org/people/mcarducci\ ?p ?o }
找到一个主语标识符:
PREFIX foaf: \http://xmlns.com/foaf/0.1/\
SELECT ?s WHERE { ?s foaf:name “Michael Carducci” }
在知道要使用哪个标识符后,您可以运行之前的查询来获取 Michael 的信息,如下:
PREFIX foaf: \http://xmlns.com/foaf/0.1/\
SELECT ?p ?o
Where
{
?s foaf:name "Michael Carducci" ;
?p ?o .
}
上面的 ?s foaf:name “Michael Carducci”
;必须要写,因为要先匹配到该模式后,再选择?p ?o 作为输出。
查询多个数据集
通过 foaf:knows 关系将 Brian 的节点连接到 Michael 的节点
PREFIX ex: \http://example.com/ns/\
PREFIX foaf: \http://xmlns.com/foaf/0.1/\
SELECT ?magician ?name
WHERE {
?s foaf:name "Brian Sletten" ;
foaf:knows ?magician .
?magician a ex:Magician ;
foaf:name ?name .
}
告诉我任何 (?s) 名叫 Brian Sletten
的人,这个人需要知道某个是 ex:Magician 类的实例 (?magician)
的人。另外,获取另一个人的姓名。查询过程如下:先匹配模式?s foaf:name
“Brian Sletten” ;并且可以连接Michael (foaf:knows
?magician)的节点的ex:Magician类型(?magician a
ex:Magician),才算匹配成功,并且返回其name值。
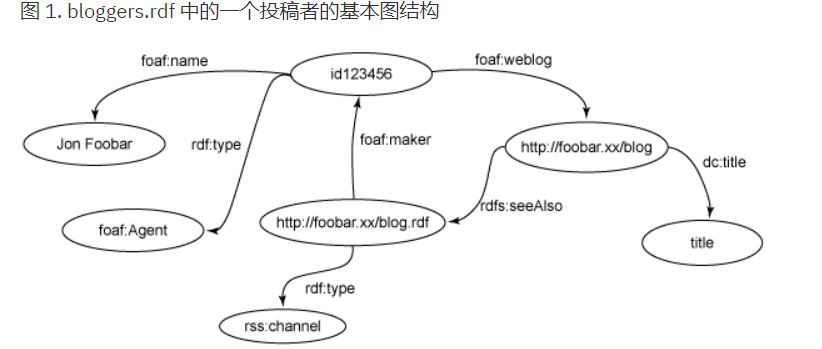
PREFIX foaf: \http://xmlns.com/foaf/0.1/\
SELECT ?url
FROM \<bloggers.rdf>
WHERE {
?contributor foaf:name "Jon Foobar" .
?contributor foaf:weblog ?url .
}
第一个三元组与 foaf:name 属性为“Jon
Foobar”的节点匹配,并且赋给contributor相应的值。在 bloggers.rdf
模型中,contributor 会和顶部的空节点id123456匹配。图形模式的第二个三元组与 contributor 的 foaf:weblog 属性对应的对象匹配。要两个模式同时匹配才算成功,最后返回url的值。
可选匹配
可选块 定义了附加图形模式,即使模式不匹配,不会造成结果被拒绝,但在匹配的时候,图形模式会被绑定到图形上
替换匹配
替换匹配的定义方式是写出多个替换图形模式,中间用 UNION 关键字连接
值约束条件
SPARQL
中的 FILTER 关键字对绑定变量的值进行约束,从而限制查询的结果。这些值约束条件是对布尔值进行计算的逻辑表达式,并且可以与逻辑操作符 && 和 ||组合使用
查找包含某个模式的图
使用 GRAPH 的另一种方法是在它后面跟一个未绑定变量。在这种情况下,图形模式被应用到查询可以使用的每个命名图中。如果模式和其中一个命名图匹配,那么这个图的
URI 就被绑定到 GRAPH 的变量上
其他:
查询所有属性
查询一个类的所有子类
查询一个类的所有超类
查询一个属性的子属性
列出一个类的所有属性
使用FILTER正则匹配:FILTER regex(?x, “pattern” [, “flags”])
SELECT DISTINCT ?p
Where {
?p a rdf:Property.
?s ?p ?o.
FILTER (REGEX(str(?p), “date”, “i”)) #
“i”代表大小写不敏感,匹配?p中出现date
}
聚合语句的写法(显示配偶信息大于1条的演员)
SELECT ?s, (COUNT(?s) AS ?cnt)
{
?s a ont:Actor.
?s prop:spouse ?o.
FILTER(isLiteral(?o))
}
GROUP BY ?s
HAVING (COUNT(?s) > 1)